Nouveaux Cahiers du socialisme
Faire de la politique autrement, ici et maintenant...


La grève politique et sociale – Introduction au dossier

Depuis quelques années, les appels à la grève politique et sociale se multiplient au Québec. En décembre 2024, le groupe Alliance Ouvrière adopte comme stratégie « la récupération de l’outil de la grève politique pour rétablir le rapport de force de la classe ouvrière[1] ». Le 25 novembre 2025, Magali Picard, présidente de la Fédération des travailleurs et travailleuses du Québec (FTQ), affirme que « la grève sociale pourrait devenir la solution ultime des syndicats[2] » pour renverser le projet de loi 3 qui vise à entraver l’action politique des travailleurs[3]. Et le 30 janvier 2026, le Conseil central du Montréal métropolitain-CSN adopte un plan d’action pour déclencher une grève sociale d’ici les prochaines élections provinciales. Si le projet se concrétise, il « combinerait des débrayages dans les milieux de travail avec des actions d’appui populaires (grèves du milieu communautaire, grèves étudiantes, mobilisation dans les quartiers et les régions, etc.)[4] ». Le premier élément, celui concernant les grèves en milieu de travail, reste à construire et c’est de lui que dépendra le succès de cette lutte. Quant à l’appui des mouvements sociaux, ce plan semble réaliste puisque les travailleuses et les travailleurs du milieu communautaire ont annoncé un premier débrayage du 23 mars au 2 avril 2026, alors que la Coalition de résistance pour l’unité étudiante syndicale (CRUES) prévoit une « semaine de grève et d’actions contre l’austérité » au même moment. Ces mobilisations pourraient servir de levier à un mouvement plus ample autour du 1er mai ou à l’automne 2026, pour casser les lois et projets de loi rétrogrades et antisyndicaux de la Coalition avenir Québec (CAQ)[5], et pour instaurer un rapport de force avec le futur gouvernement qui sera élu le 5 octobre prochain. Comme le mentionne un journal intersyndical récemment créé dans le but de mobiliser les employé·e·s du cégep de Saint-Laurent : « À ce stade, nous devons également envisager la grève […] une grève politique, contre l’austérité et contre l’atteinte à nos droits en tant que travailleuses et travailleurs[6] ».
Grèves et enjeux politiques
Mais qu’est-ce qu’une grève politique ou une grève sociale au juste ? Bien que ces termes circulent de plus en plus parmi les groupes militants, ils ne sont pas encore courants dans le reste de la population. La grève est un arrêt collectif et concerté du travail ou de ses activités, dans le but d’instaurer un rapport de force à l’encontre de l’employeur ou d’une instance dirigeante. Lorsqu’on parle de grève politique, on réfère à un arrêt de travail qui vise directement un objectif politique (faire tomber une loi ou un gouvernement, imposer une nouvelle structure de pouvoir, etc.) ou qui affecte le champ politique (parce qu’illégal ou non conforme à la loi). Au Québec, puisque le droit de grève est uniquement toléré lors des négociations pour renouveler une convention collective, on considère que toutes les grèves qui se situent en dehors des périodes de négociation sont illégales, et donc qu’elles sont politiques au sens large. De plus, n’importe quelle grève au départ économique et légale peut se politiser. Bien qu’une grève politique puisse se produire dans une seule entreprise ou à une échelle réduite, cet outil est souvent utilisé par des fronts communs ou des coalitions afin de contrer une loi ou un gouvernement autoritaire. L’extension de la grève politique à de larges secteurs de la population entraine ce qu’on appelle une grève sociale. Il y a donc une continuité entre la grève politique et la grève sociale, selon laquelle la multiplication des débrayages politiques ouvre la porte à un arrêt de travail général.
Historiquement, le droit de grève a été largement contesté par l’État bourgeois et la classe capitaliste. Au Canada, les syndicats et le droit de grève sont décriminalisés en 1872. Dans la pratique, les grèves continuent d’être réprimées et leur exercice est fortement réduit par la Loi des enquêtes en matière de différends industriels de 1907. Par la suite, profitant de la Deuxième Guerre mondiale, le gouvernement fédéral impose un cadre restrictif concernant les relations de travail qui interdit la grève en dehors des périodes de négociation pour renouveler une convention collective. Et même ce « droit de grève contrôlé » n’est accordé qu’en 1965 aux employé·e·s de la fonction publique, tout en demeurant fragile puisqu’il est régulièrement suspendu par des « lois spéciales » ou par décret. Dans ces conditions, une large part des luttes des travailleuses et des travailleurs se sont déroulées dans l’illégalité ou à la frontière de la légalité, prenant souvent la forme de grèves politiques. Bien que l’expression elle-même soit peu usitée, elle est employée au sujet de différents épisodes déterminants de l’histoire ouvrière. La grève générale de Winnipeg, en mai-juin 1919, opère une rapide transition des revendications économiques vers l’action politique, alors que les travailleuses et les travailleurs prennent le contrôle de la ville. Les conflits de travail durant les deux guerres mondiales, considérés comme illégaux par les autorités, sont de facto devenus politiques, en particulier au Québec où ils recoupaient une défiance envers les élites anglophones. La grève générale des employé·e·s du secteur public en avril 1972, suivie du débrayage spontané de centaines de milliers de travailleuses et de travailleurs en mai, ont été parmi les moments de lutte politique les plus intenses de notre histoire. Le 14 octobre 1976, plus d’un million de personnes débraient à travers le Canada pour exiger l’abolition de la Loi C-73 qui impose un strict contrôle des salaires. Par la suite, plusieurs fronts communs intersyndicaux et d’autres conflits de travail ont similairement évolué en affrontements politiques[7].
La résurgence de la grève politique
L’histoire de la grève au Canada et au Québec, qui comprend une reconnaissance légale, quoique tardive, mais aussi un encadrement réglementaire parmi les plus sévères en Occident ainsi que des mesures fréquentes de répression, explique le statut ambigu de la grève politique dans notre tradition militante et notre imaginaire de lutte. D’un côté, de nombreuses grèves passées se sont révélées politiques compte tenu de leur débordement du cadre légal. D’un autre côté, l’encadrement juridique et la répression ont eu tendance à réduire les initiatives de grève politique et sociale pensée comme telle et menée à large échelle. Cette situation équivoque n’a pas empêché l’idée de la grève politique et sociale de ressurgir. En 2004, les centrales syndicales ont appelé à une grève sociale contre les mesures austéritaires du gouvernement libéral de Jean Charest, mais le mandat n’a pas été exercé en raison du manque d’unité entre les centrales. Au printemps 2012, la grève étudiante s’est étendue à plusieurs secteurs de la population, provoquant un véritable mouvement social. En 2015, une grève conjointe des étudiantes et des étudiants et de plusieurs milieux de travail a permis de réaliser le 1er mai une grève sociale d’une certaine ampleur. Le 27 septembre 2019, de nombreux syndicats étudiants, enseignants et autres, ont débrayé pour le climat et participé à une marche d’un demi-million de personnes à Montréal. Lors de ces différents épisodes, les termes de grève politique et de grève sociale ont ressurgi, et leur popularité grandit depuis dans les syndicats et les mouvements sociaux. Ce retour de la grève politique s’explique par deux raisons : la violence des crises qui frappent les classes populaires et la force de la grève pour faire valoir nos droits.
Dans un premier temps, nous devons reconnaitre l’intensité particulière des crises qui affectent les travailleuses et les travailleurs et qui provoquent une colère légitime. Depuis la crise économique de 2008, les conditions de vie de la majorité de la population se sont dégradées, parce que les capitalistes ont fait reposer le poids de cette crise sur le dos des classes laborieuses. Afin de maximiser leurs profits, les multinationales et les grands patrons continuent d’intensifier l’exploitation des travailleurs et des travailleuses, amplifient les inégalités sociales et paupérisent davantage les plus démuni·e·s. Ces conditions maintiennent une crise perpétuelle du logement et entrainent une crise de la vie chère qui provoque désormais une insécurité alimentaire grave chez 20 % des Québécoises et des Québécois[8]. Sur un autre plan, la crise écologique s’approfondit – incluant la dégradation des milieux de vie, la multiplication des feux de forêt, des inondations, etc. – alors que rien ne laisse croire que nos dirigeants agiront pour la résorber. Au contraire, les gouvernements du Parti libéral du Canada (PLC) et de la Coalition avenir Québec (CAQ) abandonnent une à une les mesures et règlementations environnementales existantes, sans compter les efforts de Donald Trump pour dynamiter l’Accord de Paris et l’ensemble des ententes transnationales sur l’environnement et le climat. Ces phénomènes témoignent de la droitisation de la politique mondiale, canadienne et québécoise. Les factions les plus réactionnaires de la bourgeoisie s’imposent progressivement et multiplient les attaques économiques et politiques à l’encontre des classes populaires et moyennes. Les décrets anti-travailleurs du PLC, comme les lois autoritaires, liberticides et racistes de la CAQ, exposent cette droitisation des élites et font peser une véritable menace fascisante sur nos sociétés. Enfin, la résurgence du bellicisme et de l’économie de guerre détourne les budgets sociaux et ouvre la porte à un affrontement militaire d’ordre mondial, avec toutes les horreurs que cela implique[9].
Dans un deuxième temps, nous devons réfléchir aux outils dont disposent les classes laborieuses pour se défendre et imposer leur volonté, ce qui permet de comprendre à la fois l’augmentation du nombre de grèves et les raisons pour lesquelles nous devons intensifier ce mouvement. Comme dans toute société capitaliste, les travailleurs et travailleuses du Canada et du Québec disposent de peu de moyens pour faire valoir leurs intérêts et leurs besoins. Les carences démocratiques du système électoral uninominal majoritaire à un tour sont bien connues, sans compter le pouvoir disproportionné des riches et des grandes entreprises sur les décisions politiques[10]. La population est rarement sollicitée pour participer directement à la prise de décision. Pour être précis, entre 1898 et 1995, les Québécoises et les Québécois ont été appelés à se prononcer par référendum seulement six fois (trois fois à l’échelle fédérale et trois fois à l’échelle provinciale) et jamais depuis. Par contre, le Code du travail encadre strictement le droit de négociation des employé·e·s et sacralise le droit de gestion du patronat, c’est-à-dire « le droit de l’employeur de diriger ses travailleuses et travailleurs et de prendre des décisions pour assurer la rentabilité de son entreprise et la bonne marche de ses affaires[11] ». Alors, quels moyens reste-t-il aux travailleuses et aux travailleurs pour faire valoir leurs droits et pour imposer l’acceptation de leurs demandes ? D’un côté, on peut penser aux actions de visibilité et aux manifestations. Il est vrai qu’elles permettent parfois d’infléchir les décisions politiques. Néanmoins, elles n’offrent pas un véritable rapport de force et leur efficacité repose, en dernière instance, sur la bonne foi des dirigeants. D’un autre côté, il y a les actions qui viennent perturber ou arrêter le fonctionnement habituel de l’économie ou de la société. Parmi celles-ci, la grève s’impose comme moyen le plus efficace. C’est pourquoi nous sommes de plus en plus nombreux à miser sur la grève pour imposer nos revendications, voire même un projet de société alternatif.
Le dossier : des aspects de la grève politique et sociale
En regard des crises provoquées par le capitalisme et des multiples attaques gouvernementales que subit la classe ouvrière[12], de nombreuses personnes et organisations envisagent dorénavant de recourir à la grève pour faire valoir leurs droits. C’est pour accompagner cet élan que nous avons choisi de consacrer le présent dossier à « la grève politique et sociale ». Par ce travail collectif, nous souhaitons contribuer à la mise en lumière et à la diffusion de ce moyen qui, bien qu’en regain de popularité, est encore loin d’être général dans les syndicats et les groupes militants. Nous pensons que la grève politique est un outil important, tant à l’échelle locale que nationale, pour défendre nos droits, mais aussi pour potentiellement obtenir des gains inédits. Nous croyons que la pratique de la grève politique, qui vise la confrontation et l’instauration d’un rapport de force, offre une véritable possibilité de reconstruire la puissance de la classe ouvrière et de reprendre l’initiative en vue d’instaurer une société plus égalitaire. La multiplication des grèves politiques locales pourrait servir de levier à de futures grèves sociales capables d’ébranler le statu quo et d’entrainer des changements structurels, en vue d’atteindre un objectif qui figure dans le nom même de cette revue : le socialisme. Pour contribuer à ce vaste programme, notre dossier se divise en trois sections, qui traitent successivement de la théorie de la grève politique, de son histoire au Canada et, enfin, de sa pratique et de ses perspectives au XXIe siècle.
La première partie du dossier aborde la théorie et la stratégie de la grève politique et sociale. Les deux premiers articles posent les bases d’une compréhension historique de cette pratique, en étudiant respectivement la place de la grève dans la pensée de Karl Marx (Isabelle Le Bourdais et Olivier Dupuis), puis l’expérience de l’Internationale syndicale rouge et de sa stratégie de grèves politiques dans les années 1930 (Alexis Lafleur-Paiement). Par la suite, deux textes analysent l’imbrication entre le syndicalisme québécois et l’action politique. Dans son article, Émile Lacombe étudie le concept du « syndicalisme de combat » élaboré par Jean-Marc Piotte, qui a durablement marqué la gauche québécoise. Pour sa part, Yvan Perrier propose une longue étude des fronts communs intersyndicaux de 1972 à nos jours, pour montrer à la fois leur force politique et leurs limites reliées aux pouvoirs de l’État capitaliste. Ensuite, Judith Trudeau étudie les liens entre le syndicalisme, les pratiques de grève et les luttes féministes, éclairant le rôle que l’action syndicale et la grève peuvent jouer dans l’émancipation des femmes. Pour conclure cette première partie, Benoît Dumais traite de la stratégie de l’organisation Alliance Ouvrière, qui promeut depuis quelques années l’usage de la grève politique pour accroitre la force des travailleuses et des travailleurs.
La deuxième partie du dossier présente cinq moments où des grèves ont ébranlé le statu quo politique. D’abord, Marie-Josée Lavallée analyse la grève générale de Winnipeg de 1919 et la peur qu’elle a provoquée au sein des élites politiques conservatrices, notamment la peur du bolchévisme. Cet épisode permet de comprendre les manœuvres subséquentes des classes dirigeantes pour restreindre le droit de grève au pays. Ensuite, Raphaël Simard étudie la grève à l’usine d’Alcan d’Arvida en 1941, une grève spontanée qui fut durement réprimée puisqu’elle touchait l’aluminium, une industrie stratégique en pleine Deuxième Guerre mondiale, et qui n’a apporté que de faibles gains pour les ouvriers. Le texte suivant présente une entrevue avec l’historien Martin Pâquet qui revisite les luttes ouvrières des années 1970 et leur portée politique, en inscrivant cette période dans le temps long et en soulignant comment l’affrontement entre les travailleurs et les travailleuses contre le patronat recèle toujours un enjeu politique. Dans l’avant-dernier texte de la section, Raphaël Laflamme aborde les grèves politiques qui ont eu lieu aux Philippines dans les années 1970 et 1980, et qui ont contribué à la chute de la dictature de Ferdinand Marcos en 1986. Enfin, Laurence Hamel-Roy retrace la lutte des travailleuses et des travailleurs de la construction au début des années 1990, plus précisément leur combat pour maintenir la syndicalisation dans le secteur résidentiel que le gouvernement voulait supprimer. Malgré une victoire pour le maintien des syndicats dans ce secteur, les travailleurs du résidentiel sont depuis moins payés et moins bien traités que leurs collègues des autres secteurs.
La troisième et dernière partie du dossier expose différentes expériences récentes de grèves politiques et sociales, en ouvrant sur les possibilités de relancer ces pratiques aujourd’hui. Les deux premiers textes traitent des grèves étudiantes de 2012 et de 2015. Dans son article, Jeanne Reynolds discute de la préparation qui fut nécessaire pour faire naitre le mouvement de grève étudiante historique de 2012, et montre comment celui-ci s’est transformé en mouvement social. Pour sa part, Jasmin Cormier explique comment des étudiants et étudiantes ainsi que des travailleurs et travailleuses ont développé le mouvement de grève du printemps 2015, et par quels moyens ils ont réussi à mener une grève sociale le 1er mai. Ensuite, Félix Trudeau aborde la syndicalisation d’un entrepôt d’Amazon à Laval en 2024, puis la fermeture des installations de la compagnie au Québec en représailles et la lutte politique qui a suivi. Dans le dernier texte du dossier, André-Phillipe Doré revient sur plusieurs grèves politiques et sociales récentes, pour en faire une synthèse et montrer comment ces expériences peuvent nous inspirer pour l’avenir.
En explorant tour à tour les enjeux théoriques, historiques et contemporains de la grève politique et sociale, nous souhaitons contribuer à redonner sa place à une forme d’action mal connue au Québec, mais porteuse de véritables possibilités transformatrices. Cela dit, nous sommes conscients et consciente que cette pratique ne pourra exister que si les syndicats locaux, les organismes communautaires et les groupes militants s’en emparent. Dans la foulée de ce dossier, nous invitons les militantes et les militants à réfléchir aux manières de joindre leurs forces aux organisations qui préparent des grèves politiques et sociales pour l’année 2026. Nous ne pouvons pas compter sur les pompiers pyromanes qui sont aux commandes du gouvernement et des entreprises pour régler les crises qui affectent les classes populaires et moyennes. À l’orée du Front commun intersyndical de 1972, la CSN lançait le manifeste Ne comptons que sur nos propres moyens[13] qui a mis la table pour la plus importante grève politique de l’histoire du Québec. Il est temps de renouer avec cette proposition et de faire valoir nos exigences par une lutte audacieuse.
Par André-Philippe Doré, Alexis Lafleur-Paiement, Flavie Achard, responsables de la coordination du dossier
- Alliance Ouvrière, Un mouvement politique pour la classe ouvrière, Montréal, décembre 2024, p. 9. ↑
- Hugo Pilon-Larose, « Les syndicats brandissent la menace d’une grève sociale », La Presse, 25 novembre 2025. ↑
- Le projet de loi 3 veut imposer aux syndicats une série de « règles touchant à la transparence, à la gouvernance et au processus démocratique » et cherche à restreindre ainsi la voix des syndicats. Le texte introduit notamment la notion de cotisations syndicales « facultatives » pour les activités n’étant pas en lien direct avec les négociations des contrats de travail, comme la participation à un mouvement social ou la contestation de la validité d’une loi. ↑
- Roger Rashi, « Le Conseil central de Montréal (CSN) adopte un plan d’action menant à la grève sociale », Presse-toi à gauche, 10 février 2026. ↑
- En plus du projet de loi 3 déjà mentionné, soulignons la loi 14 (PL 89) adoptée en mai 2025 et appliquée depuis le 1er novembre 2025. Elle élargit la définition des services essentiels qui doivent être maintenus lors d’une grève ou d’un lockout, tout en permettant au ministre d’imposer un arbitrage exécutoire aux parties lors d’un conflit de travail, même si elles sont toujours en médiation. ↑
- Charles G., « Énoncé pour le droit à la grève politique », Le babillard, no 1, janvier 2026, p. 11. ↑
- Sur l’histoire du droit de grève au Québec et de sa répression continue, voir Martin Petitcelerc et Martin Robert, Grève et paix. Une histoire des lois spéciales au Québec, Montréal, Lux, 2018. ↑
- Geoffroy Boucher et François Fournier, « L’insécurité alimentaire grave en forte hausse au Québec », Observatoire québécois des inégalités, 1er mai 2025. ↑
- Dans cette situation, il est impératif que la gauche canadienne ne fasse pas l’erreur d’appuyer sa bourgeoisie nationale pour contrer la bourgeoisie étatsunienne, mais qu’au contraire, elle fasse la promotion d’un véritable internationalisme ouvrier. Voir David Camfield, « Comment la gauche doit répondre aux menaces de Trump contre le Canada ? », Archives Révolutionnaires, 7 février 2026. ↑
- La gauche québécoise a tenté à plusieurs reprises de lancer des partis électoraux, par exemple le Parti socialiste du Québec (1963-1968) et Québec solidaire (depuis 2006). Néanmoins, on constate à quel point il est difficile de faire valoir une option réellement de gauche dans la structure électorale actuelle, alors que les formations progressistes sont coincées entre les injonctions médiatiques à modérer leur discours et un système qui favorise les partis établis. À ce sujet, voir François Saillant, Brève histoire de la gauche politique au Québec, Montréal, Écosociété, 2020. ↑
- « Droit de gestion », CNESST, consulté le 11 février 2026. ↑
- Pour un aperçu des attaques contre les travailleurs et travailleuses au Canada et au Québec, voir Harry Glasbeek, « Comment les libéraux fédéraux sapent le droit de grève », Nouveaux Cahiers du socialisme, no 34, automne 2025, p. 155-162, ainsi que Thomas Collombat, « Le PL89 ou quand la CAQ tire à boulets rouges sur le droit de grève », Nouveaux Cahiers du socialisme, no 34, automne 2025, p. 163-170. ↑
- CSN, Ne comptons que sur nos propres moyens, Montréal, Conseil confédéral, 6 octobre 1971. ↑

Riposter à l’attaque aux droits par l’interdépendance des droits

Autour du 1er mai 2026, au Québec, plusieurs initiatives qui relaient la vague de mobilisations de l’automne 2025 se conjuguent ou se superposent pour exprimer le tollé soulevé par les attaques tous azimuts contre les droits syndicaux et du communautaire et les droits d’exercice de la citoyenneté civile et politique. Autant de droits qinteri ont souvent été arrachés à l’issue de dures luttes – que l’on songe au droit de grève à présent restreint par la loi 89 – et qui constituent de nécessaires contre-pouvoirs, comme le sont certaines institutions, tels les tribunaux, eux aussi de plus en plus contournés par l’utilisation répétée de la clause dérogatoire et par la cascade de lois et projets de loi pilotés par le gouvernement caquiste de François Legault ainsi que par les gouvernements libéraux successifs de Justin Trudeau et Mark Carney[1].
Cette montée de l’autoritarisme mise en évidence par les attaques répétées contre les droits[2] prend tout son sens dans le contexte ouvertement « va-t-en guerre » marqué par la hausse des budgets militaires et couronné par la décision de Trump et Netanyahou d’attaquer l’Iran, semant ainsi la mort parmi les populations du Moyen-Orient. Toute dénonciation de cette politique impérialiste attire les menaces ou les sarcasmes du fasciste Trump à l’encontre de leurs auteurs, soient-ils chefs d’État. Mais dans de nombreux pays déjà, tout citoyen ou citoyenne qui s’oppose même pacifiquement aux abus et aux violences antidémocratiques, ou proteste contre l’adoption de politiques inégalitaires, court aujourd’hui le risque d’aller en prison ou même de perdre la vie. En réalité, on assiste depuis plusieurs années déjà à la judiciarisation des conflits et à la montée en violence de la répression policière dans nombre de pays considérés comme des démocraties. C’est un mouvement convergent de criminalisation de la contestation politique et des opposants et opposantes, typique d’un processus de fascisation par le haut.
Non à la restriction des droits
Comme le rappelait France-Isabelle Langlois, la directrice d’Amnistie internationale Canada francophone lors d’une audition en commission parlementaire sur le projet de loi 1 (PL1), la restriction des droits, « on sait où cela commence, on ne sait jamais où cela finit[3] ». Dénonçant la vision gouvernementale de la laïcité, elle soulignait que le sujet n’était pas de savoir si on était « pour ou contre le port du voile », mais si on était « pour ou contre la restriction des droits ».
La criminalisation de la contestation politique commence toujours par la criminalisation de boucs émissaires. Au Québec, on peut aisément rendre visible le processus qui a conduit des attaques ciblées contre des catégories de personnes par la remise en cause généralisée des contre-pouvoirs institués. Il a démarré avec les déclarations et les lois islamophobes puis les discours, tenus par des responsables de presque tous les partis politiques (à l’exception du Nouveau Parti démocratique et de Québec solidaire) jusqu’aux gouvernements fédéral et provincial, de diabolisation des personnes demandeuses d’asile et migrantes temporaires – celles-là mêmes qui étaient appelées « anges gardiens » pendant la pandémie. Le tout a soutenu le déploiement d’un autoritarisme identitaire mis en œuvre de façon rampante, c’est-à-dire sans le bruit et la fureur des violences commises par ICE aux États-Unis contre les personnes migrantes et les citoyens et citoyennes solidaires. Pour l’instant, car avec la loi fédérale C-12 et le renforcement des pouvoirs des agents frontaliers, il est à craindre que se multiplient encore les arrestations et les déportations de personnes migrantes dont le seul « crime » est d’avoir perdu leur statut, ou de ne pouvoir obtenir la régularisation de leur situation en conséquence des politiques d’immigration à plusieurs vitesses et de leurs règles changeantes sans préavis[4].
Cependant, la restriction de droits est souvent euphémisée quand elle « ne fait que » s’en prendre à des groupes sociaux présentés comme des minorités. Le sens commun a tendance à percevoir les droits des groupes minorés, c’est-à-dire dominés dans les rapports sociaux, que ces groupes soient ou non minoritaires, comme « spécifiques » à ces groupes. Ce n’est bien sûr pas le cas. Ces droits visent en réalité à encadrer par la loi des rapports sociaux de domination et d’exploitation pour les limiter, voire les annihiler. L’objet des chartes – elles aussi contournées depuis la loi 21 sur l’interdiction du port du voile aux personnes en autorité dont les enseignantes, interdiction étendue aujourd’hui avec la loi 94 et le projet de loi 9 aux éducatrices et parents bénévoles des services de garde – est d’empêcher que les droits des groupes minorés, ou tout simplement leur possibilité d’exercer les droits reconnus normalement à toute et tout citoyen ou travailleur, ne soient niés ou piétinés par la majorité, ou par le groupe dominant, qui n’est pas nécessairement majoritaire en nombre. Soulignons, par ailleurs, que les attaques contre les femmes voilées sont des attaques contre le droit des femmes à disposer de leur corps et, jusqu’à nouvel ordre, les femmes ne constituent pas une minorité.
Mais pour le sens commun, tout se passe comme si s’attaquer à ces droits qualifiés de « spécifiques », et à ce titre perçus comme des avantages, préservait les droits considérés comme « universels ». Jusqu’au jour où, d’attaque en attaque, le voile d’illusions se déchire car même les droits dits universels sont remis en cause. C’est le cas actuellement au Québec avec le projet de loi 1 sur une future constitution québécoise, élaborée de façon condescendante, sans réelle consultation, qui nie la reconnaissance des Autochtones comme peuple et qui remet en cause l’État de droit.
Mais quoi de surprenant ? Autoritarisme et fascisation ne sont jamais le fait d’un groupe d’extrême droite isolé. Si l’on fait le tour des démocraties occidentales où de telles dynamiques se déploient, on constate qu’elles sont conduites par les gouvernements eux-mêmes, qui privilégient les intérêts des classes dirigeantes et des milieux d’affaires, et cherchent à éliminer les freins aux processus d’accumulation de richesses[5]. Au point qu’il ne semble plus y avoir de limites à la prédation qui soutient ces processus depuis l’arrivée au pouvoir de Trump et sa mise à mort d’un ordre mondial qui n’avait rien de juste ni d’égalitaire, mais qui reposait sur certaines règles prévisibles ou discutées, telles les tentatives de limitation des changements climatiques. Carney a d’ailleurs pris acte de ce changement de paradigme dans son discours à Davos, qui appelait à une redistribution des alliances entre classes dirigeantes. Peut-être s’est-il montré prêt à accepter dans la « gang » quelques pays malmenés par les rapports de force globaux, pour autant que cela perpétue un système où la marchandisation du travail, de la nature et de tout le vivant prime sur le respect des peuples et sur leur droit à disposer d’eux-mêmes.
L’interdépendance des droits
Si l’on se recentre sur les contestations et mobilisations en cours au Québec, on peut constater qu’elles s’expriment aujourd’hui avec la volonté de faire converger l’ensemble des luttes et d’étendre le droit de grève à des enjeux dépassant la seule convention collective, afin de mener des grèves sociales contre les attaques tous azimuts aux droits. Cependant, il n’est pas acquis que soit rendue visible l’interdépendance des droits, et donc la nécessité de revendiquer un ensemble de droits indissociables. Car une attaque à un droit est une attaque à toute l’armature des droits ; et une attaque aux droits d’un groupe, aussi minoritaire ou minoré soit-il, est une attaque portée contre le droit de tous et toutes à avoir des droits. Partir de cette prémisse est une condition pour que des grèves sociales relaient les volontés de transformations sociales, économiques et sociétales des classes travailleuses et populaires, qui sont plurielles et diverses.
Sans doute une éducation populaire sur la nécessité de prendre en compte et de protéger tous les droits y compris ceux des minorités ou des groupes minorés – par exemple en intégrant dans les plateformes revendicatives le respect des droits de ces groupes minorés – serait bienvenue, au risque sinon de laisser ouverte la porte pour que cela recommence dès que des élu·e·s voudront se dédouaner de leurs responsabilités, comme le fait aujourd’hui la CAQ face à la croissance des inégalités dans tous les domaines. Ces inégalités se traduisent notamment par : la réduction de l’accès aux services publics et en particulier au droit à la santé ; la crise de l’abordabilité des logements et un manque criant de logement social, source d’une forte montée de l’itinérance ; le maintien d’un système d’éducation à trois vitesses qui écarte les classes populaires de choix de vie et de carrière rémunérateurs et valorisants ; une pauvreté insurmontable quand on n’a plus accès à la couverture de chômage ou qu’on se retrouve sur l’aide sociale, dont le montant des prestations est indigne d’un pays qui se veut démocratique comme le Québec ; l’abandon des personnes handicapées en les privant d’aide à la mobilité ; etc.
Cette énumération nous rappelle que l’interdépendance des droits provient aussi du fait que les droits civils et politiques ne peuvent être pleinement exercés sans une armature de droits sociaux (droit à l’éducation, à la santé, au logement, à de l’aide sociale et à des prestations de chômage dignes de ce nom, à des conditions de travail décentes[6], à des services publics et à des services de garde pour toutes et tous, etc.) qui contrecarrent les inégalités matérielles et symboliques engendrées par les différents types de domination et d’exploitation inscrits dans les rapports sociaux de genre, de race, de classe, pour citer les principaux rouages des inégalités dans nos sociétés.
Comme évoquée ci-dessus, la pleine prise en compte de l’interdépendance des droits inclut un positionnement solidaire avec les peuples opprimés par des dictatures ou des occupations coloniales génocidaires, comme c’est le cas notamment du peuple iranien ou du peuple palestinien, en respectant et en faisant en sorte de faire respecter leur droit à l’autodétermination, qui ne peut rimer avec des interventions militaires par ceux-là mêmes qui commettent les génocides ou par ceux qui leur vendent des armes. L’implosion en cours du système de droit international qu’est l’ONU pourrait être saisie comme une occasion de réécrire un droit international qui encadre les marges de manœuvre des pays dominants, au lieu de donner un droit de veto aux puissances impérialistes qui siègent au Conseil de sécurité de l’ONU.
Ce positionnement solidaire suppose aussi que l’on connaisse et reconnaisse les inégalités globales entre pays dominants et dominés, notamment pour revoir le droit local, mais aussi le droit international en matière d’immigration, afin qu’il ne soit plus possible d’exploiter des travailleuses et des travailleurs étrangers avec des permis fermés ou des statuts temporaires ne donnant pas accès à la résidence permanente dès l’entrée au pays recruteur et la mise en œuvre du contrat de travail. L’objectif pourrait être de créer une sorte de citoyenneté internationale de la migration, ou d’attacher les mêmes droits à toute personne migrant pour travailler dans un autre pays.
Au Québec, à l’heure où la question de la défense des droits s’impose comme un enjeu commun, et pour que les luttes convergent, il est nécessaire de partager une compréhension des rouages des rapports sociaux de domination, d’oppression et d’exploitation dans les différents lieux de mobilisation et de convergence. Partager comment ces rapports sociaux transforment la mise en œuvre des droits dits universels, comme le droit d’expression ou le droit de revendiquer, en parcours d’obstacles pour les groupes minorés, qu’ils soient minoritaires ou quasi majoritaires, comme le sont les femmes. Partager aussi une connaissance des répercussions de l’absence d’un socle de droits sociaux pour contrecarrer des inégalités empêchant de s’approprier le droit à l’éducation ou à la santé ou d’exercer ses droits civils et politiques. Partager également une connaissance des contraintes de tous ordres pesant sur des peuples qui sont étouffés par les diktats économiques imposés par des pays dominants.
Comment organiser cette diffusion et ce partage des connaissances à même de rendre effectives les possibilités de convergence et de créer des liens solides entre les différentes mobilisations ? Sans doute en partant de la parole et de l’expérience des premières et premiers concernés. Ce travail de reconnaissance mutuelle entre actrices et acteurs des mobilisations s’opère déjà à travers diverses initiatives qui montrent le souci de nombre d’organisations communautaires de faire vivre une intersectionnalité des luttes, en rendant visibles les différentes dimensions qui s’entrecroisent dans les enjeux qu’elles affrontent et sur lesquelles elles revendiquent. Ainsi, la Fédération des femmes du Québec veut éclairer l’importance de prendre en compte les droits des femmes migrantes pour réellement défendre les droits des femmes. Le Front d’action populaire en réaménagement urbain (FRAPRU) dénonce de son côté non seulement l’instrumentalisation d’un discours anti-migrant pour masquer les véritables causes de la crise du logement, en particulier du logement social, qui ne date pas de la croissance du nombre de travailleurs temporaires, mais qui remonte à plus d’une vingtaine d’années, ainsi que le fait que ce sont les personnes migrantes qui logent le plus souvent dans les taudis insalubres. De même, les luttes pour l’environnement n’ignorent plus que ce sont les populations pauvres ou à bas revenu dans les villes occidentalisées ou dans les pays anciennement colonisés, qui sont aussi les premières victimes des changements climatiques et de la pollution.
Relier ces différents éclairages et connaissances à une analyse systémique des sources d’inégalités, pour revendiquer un système de droits qui ne laisse personne au bord de la route, apporterait à ces revendications de réforme de la société une dynamique transformatrice susceptible de mettre en cause les racines mêmes de ce système mondial prédateur et extractiviste.
Par Carole Yerochewski pour le comité de rédaction
- En plus de la loi 89 déjà citée, nommons entre autres le projet de loi 3 sur la cotisation facultative et la limitation du pouvoir des syndicats de contester une loi ; le projet de loi 7 qui attaque l’autonomie des groupes communautaires et limite la protection contre la censure institutionnelle ; le projet de loi 13 sur la sécurité publique qui porte atteinte au droit de manifester, la loi 84 sur l’intégration à la nation québécoise, etc. ↑
- Voir Carole Yerochewski, « Le nationalisme identitaire comme justificatif de l’autoritarisme au Québec. Entrevue avec Paul-Étienne Rainville, historien », Nouveaux Cahiers du socialisme, n° 34, automne 2025. ↑
- Voir l’extrait à : <https://www.facebook.com/reel/1671343007317606>. ↑
- Voir notamment : Carole Yerochewski, « Menace fasciste, boucs émissaires et défense des personnes migrantes », Nouveaux Cahiers du socialisme, n° 33, printemps 2025 ; Charline Caro, « Abolition du PEQ – Des vies brisées par le rêve québécois », La Converse, 21 novembre 2025. ↑
- En témoigne au Canada l’adoption à marche forcée par le gouvernement Carney de la loi C-5 sur les grands projets d’infrastructures qui nie les droits autochtones et sa décision de ne plus poursuivre l’objectif d’abaissement des émissions de gaz à effet de serre. ↑
- Au sens de l’Organisation internationale du travail (OIT). Cela comprend un salaire minimum décent, la protection sociale, le respect du droit d’association syndicale et des droits des travailleuses et travailleurs, en particulier le droit à la santé et à la sécurité dans l’exercice du travail, ce dont beaucoup de travailleuses et travailleurs migrants sont privés aujourd’hui, y compris au Canada et au Québec. ↑

Note de lecture – Les nouveaux serfs de l’économie

Les nouveaux serfs de l’économie
Yanis Varoufakis, Paris, Les liens qui libèrent, 2024
« Le capital existe toujours et fructifie, même si le capitalisme n’existe plus » (p. 87). Cette citation de Yanis Varoufakis constitue un condensé de la thèse défendue par l’auteur dans cet ouvrage. Elle donne à la fois le ton adopté pour étayer les démonstrations et fournir les « preuves » à l’appui de cette thèse qui ne peut qu’être matière à controverse ; le cas échéant, ce ne pourra être qu’une controverse fructueuse. L’idée défendue par cet ancien ministre grec des Finances n’a rien d’arbitraire ou de farfelu car elle s’inscrit d’emblée dans la tradition marxiste de la critique du capitalisme, se revendiquant elle-même du matérialisme historique dans ses analyses, sa compréhension et son interprétation de l’évolution des phénomènes socio-économiques.
« Au début était la technique ». Voici la prémisse de base de l’argumentaire de Varoufakis qui prétend observer un changement « structurel » dans les façons de faire du capitalisme, à l’image de celui que l’Europe a vécu au tournant du XIXe siècle avec l’industrialisation à grande échelle des moyens de production. Dénouement logique, en quelque sorte, à la suite du retour du libéralisme classique dans les années 1980, le capital « cloud », tel que l’auteur le définit[1], sape les fondements de l’économie de marché capitaliste dans la mesure où la recherche du profit, qui servait de motif aux pratiques commerciales des propriétaires d’usines, de manufactures, de raffineries, a disparu des préoccupations des géants de la tech, remplacée par la rente cloud, de la même manière que les seigneurs féodaux prélevaient la rente foncière auprès de la paysannerie réduite au servage.
Ce que l’on pourrait interpréter comme étant une nouvelle phase du capitalisme, le « techno-féodalisme », transforme profondément notre rapport au capital, devenu « virtuel », insaisissable par les moyens traditionnels utilisés au lendemain de la Seconde Guerre mondiale, réunis sous l’appellation Accords de Bretton Woods, qui fixaient des limites et des cadres financiers clairs à l’échelle internationale, une parité fixe entre l’or et le dollar afin d’éviter les débordements « spéculatifs » comme ceux que l’Occident a vécus en 1929, donnant lieu à une crise économique sans précédent dans l’histoire moderne.
Avec l’annonce, en 1971, de la fin de la convertibilité du dollar en or, ainsi que des taux de change fixes avec le mark allemand et le yen japonais, Nixon sonna le début de la fin d’un semblant d’ordre international fondé sur des règles dans lequel l’État capitaliste jouait un rôle d’arbitre, de modérateur, afin de maintenir un certain équilibre entre les diverses économies du monde développé (États-Unis, Japon, Allemagne). D’excédentaire jusque-là, la balance commerciale américaine devint déficitaire et inaugura le creusement d’une dette abyssale financée par les concurrents commerciaux des États-Unis, à commencer par la Chine qui, comme un serpent qui se mord la queue, utilise les milliards qu’elle accumule en inondant le marché américain de ses biens manufacturés, pour investir dans l’immobilier, les bons du Trésor, les produits financiers étatsuniens.
Ce processus de dollarisation de l’économie mondiale va trouver son aboutissement avec la crise des subprimes et l’avènement de ce que l’auteur appelle le « socialisme au service des banques », système financier basé sur la création ex nihilo de monnaie par les banques centrales (nord-américaines, européennes, japonaises) pour venir en aide aux banques privées en manque de liquidités à la suite de la chute des prix de l’immobilier en 2008, et pour soutenir et redynamiser l’économie pendant et après la pandémie de COVID-19, en 2020-2022. Dans les faits, ces politiques monétaires renforcent le pouvoir des grandes entreprises et des géants de la tech qui ne redirigent pas ces milliards de dollars, offerts en cadeau, dans l’investissement productif, la création d’emplois, la modernisation des infrastructures, mais dans l’activité boursière, la spéculation immobilière, les produits dérivés. Bref, la générosité de l’État profite essentiellement au secteur financier, au capital cloud, aux rentiers et aux actionnaires.
Ce qui change, essentiellement, avec le technoféodalisme, c’est la nature même de la marchandise échangée entre les différents acteurs de la chaine de production/consommation ; alors qu’avant 2008, les capitalistes payaient des spécialistes en marketing et en publicité pour nous vendre des voitures, des téléviseurs, des ordinateurs, du shampoing, des boissons gazeuses, aujourd’hui, ils paient les propriétaires de plateformes numériques pour avoir accès au temps que nous passons sur les réseaux sociaux, sur notre portable, sur Internet, bénéficiant de l’illusoire gratuité de toutes ces applications alors qu’en fait, toutes et tous les utilisateurs, habitués, visiteurs et clients des différents sites Web gérés par les GAFAM ne sont rien d’autre que des « techno-serfs » qui contribuent à enrichir les propriétaires de fiefs cloud par l’entremise des « techno-prolos » que sont les employé·e·s d’Amazon, d’Uber et tous les entrepreneurs qui dépendent de plus en plus du capital cloud pour faire prospérer leurs entreprises dans le monde « réel » des échanges commerciaux.
Bref, l’« attention » des usagères et usagers des nouvelles technologies constitue le nouvel objet de convoitise de ce capitalisme cloud qui s’est libéré des « lois » traditionnelles du marché telles que les capitalistes de l’ère industrielle les avaient élaborées. L’auteur y voit une emprise décuplée des géants de la tech sur l’ensemble de nos comportements, habitudes de consommation, façons de travailler, de nous divertir, de nous informer, de nous éduquer, etc. Du coup, tout comme Marx voyait dans les contradictions du capitalisme (qui en constituent l’essence même) les germes de la Révolution prolétarienne, Varoufakis voit dans le technoféodalisme l’occasion d’un renversement radical des rapports sociaux de production dans la mesure où le caractère « cloudaliste » (c’est-à-dire abstrait, immatériel, « infonuagique ») de la nouvelle économie fragilise son ancrage dans le réel et la rend ainsi vulnérable aux initiatives rebelles qui peuvent mobiliser un nombre incalculable d’intervenants pour, par exemple, faire chuter le cours des actions d’Amazon par une synchronisation d’arrêts de travail de 24 heures sur un territoire donné, conjuguée à une non-utilisation de la plateforme pendant un certain laps de temps, question de créer une mini-panique à la bourse et ainsi de déstabiliser les conglomérats qui se financent à même ce capital dématérialisé.
Bref, « […] nous faisons l’expérience d’une forme inédite de servitude, tout en ayant sous la main une occasion en or, jusqu’alors inexistante, de réaliser “ton” rêve d’un communisme libéré du travail et vecteur d’émancipation par en bas[2] » (p. 288). Tout en reconnaissant la pertinence de cette observation qui s’inscrit dans une conception dialectique de l’histoire, comme on la retrouve chez Marx (qui s’est lui-même inspiré de celle du Maître et de l’esclave chez Hegel), il faut aussi souligner les problèmes qu’elle n’arrive pas d’emblée à résoudre comme ceux qui se sont posés chez les marxistes au tournant du XXe siècle lorsque le prolétariat s’est massivement engagé, chacun dans son armée nationale respective, pour participer à une guerre impérialiste voulue par la bourgeoisie, dirigée par la bourgeoisie, au profit de la bourgeoisie. En d’autres termes, même lorsque les conditions révolutionnaires sont réunies, rien ne garantit que le peuple va saisir l’occasion pour s’émanciper de la tutelle de ceux qui l’exploitent. Conséquemment, rien ne nous assure que les moyens dont notre monde dispose aujourd’hui vont servir à renverser le pouvoir technoféodal des cloudalistes afin d’instaurer une société axée sur les « communs » plutôt que sur la recherche toujours inassouvie de l’intérêt personnel. La fracture sociale qui accentue toujours plus les inégalités peut s’élargir encore longtemps avant que les solutions proposées par Yanis Varoufakis puissent commencer à être mises en œuvre.
Par Mario Charland, détenteur d’une maîtrise en philosophie de l’Université du Québec à Trois-Rivières
- « Il est possible de définir le capital cloud […] comme l’agrégation en réseau de machines, de logiciels et d’algorithmes pilotés par l’IA et d’infrastructures de communication sillonnant l’ensemble de la planète et exécutant un large éventail de tâches », p. 311. ↑
- . Tout au long de l’ouvrage, l’auteur s’adresse à son père (« “Ton” rêve »), maintenant décédé, ancien résistant communiste à l’époque des Colonels, emprisonné pendant plusieurs années et qui n’a pas pour autant renoncé à ses convictions politiques. C’est en sa mémoire que Varoufakis fils rédige cette critique du technoféodalisme qui a succédé au capitalisme que son père avait courageusement combattu. ↑

Note de lecture – Marx contre les GAFAM, le travail aliéné à l’heure du numérique

Marx contre les GAFAM, le travail aliéné à l’heure du numérique
Stéphanie Roza, Paris, PUF, 2024
La gauche est désorientée. Les raisons en sont multiples, mais, selon Stéphanie Roza, la raison principale est qu’elle ne propose plus une vision claire du monde et du capitalisme contemporain. Pour Roza, si l’on veut défendre une perspective socialiste et émancipatrice, il faut développer une théorie critique de la société contemporaine. La tradition marxiste, en particulier le marxisme humaniste, dispose, selon elle, des outils théoriques pour construire une telle théorie.
La première partie de l’ouvrage présente le cadre théorique, lequel s’inspire des travaux de Georg Lukacs et Henri Lefebvre, les deux principaux penseurs du marxisme humaniste. Le projet de Georg Lukacs est de fonder ontologiquement la pensée marxiste. Il s’inspire du concept d’homme générique, central dans la pensée du jeune Marx. Le concept d’aliénation fait implicitement référence à une nature humaine. Pour Lukacs, la nature humaine est le produit d’un processus historique d’humanisation. Le travail est au fondement de la spécificité de l’espèce humaine. Seul l’être humain peut produire ses moyens de subsistance. Le travail constitue une activité essentiellement sociale et consciente. Il suppose la capacité de faire des choix, ce qui ouvre la possibilité d’une liberté qui ne peut s’exercer qu’en se soumettant à la nécessité des lois de la nature. C’est à partir de l’activité productive que se développent les institutions sociales plus complexes, la politique, le droit, l’art. La nature humaine n’est pas, de ce point de vue, une essence immuable, mais le résultat d’un processus historique concret d’autoréalisation. L’aliénation résulte de l’impossibilité de satisfaire les exigences d’autonomie individuelle et collective inscrites dans cette nature.
Les outils théoriques développés dans les deux tomes de L’Ontologie de l’être social (2011 et 2012), le dernier ouvrage de Lukacs, serviront à l’analyse des rapports socioéconomiques dans le monde contemporain. L’avènement du néolibéralisme a métamorphosé les conditions de travail par la réduction des coûts de production, la déréglementation et l’externalisation de la production. La dérèglementation du système bancaire a, quant à elle, entrainé la mondialisation de la finance et de la production. Selon l’autrice, ces changements, s’ils ont eu des effets bénéfiques, la réduction de la pauvreté, par exemple, ont aussi engendré une inégalité extrême et de nouvelles contraintes au travail. Le néolibéralisme vise à rationaliser tous les aspects de la production. Toutes les activités sont quantifiées et contrôlées pour éviter tout gaspillage, les cadences sont infernales. Cette nouvelle organisation du travail produit de nouvelles « pathologies du travail qui sont avant tout psychiques » (p. 177). Ces pathologies résultent des injonctions contradictoires du management néolibéral qui accorde plus d’autonomie aux travailleurs et travailleuses, mais les condamne à l’insécurité. Selon Roza, le néolibéralisme, par la recherche du profit maximal, instrumentalise le besoin d’autonomie et de réalisation de soi des travailleurs. Il manipule les aspirations de ceux-ci. La manipulation, selon Lukacs, est une forme d’aliénation engendrée sciemment dans l’intérêt du pouvoir.
Dans les années 1990, les outils informatiques deviennent incontournables ; cependant, ce sont les plateformes qui bouleversent le plus la production et les rapports sociaux. Les serveurs, grâce à des applications, mettent en relation des prestataires de services indépendants ainsi que des clients et clientes qui utilisent ces services. Pour Roza, Uber constitue un cas d’école. Les travailleuses et travailleurs ne sont plus des salariés, mais des auto-entrepreneurs ; ils ne seraient donc pas exploités au sens marxiste. Stéphanie Roza estime que le succès d’Uber repose en fait sur une manipulation à grande échelle des clients, des chauffeurs, de l’opinion publique et des décideurs politiques, manipulation qui passe à la fois par le discours et l’incitation financière pour faire croire en l’efficacité supérieure d’Uber. De même, la liberté des prestataires est illusoire. Ce sont des algorithmes qui gèrent les rapports entre prestataires et clients, l’intervention humaine est occultée. Les plateformes instrumentalisent le désir d’autonomie des travailleurs et travailleuses. L’idée de la fin du travail n’est qu’un fantasme ; le travail n’est pas disparu, il est occulté et sous-payé, il est déplacé. Une armée de tâcherons travaille dans l’ombre pour soutenir la machine et fournir des contenus, produisent de la valeur et « relèvent à ce titre de la catégorie de travail » (p. 163). Le microtravail permet aussi l’externalisation de tâches réalisées par des travailleurs indépendants peu qualifiés. L’autrice donne l’exemple du portail Mechanical Turk qui permet à Amazon d’externaliser à peu de frais des tâches à des « partenaires » peu qualifiés.
Roza s’inspire de la Critique de la vie quotidienne d’Henri Lefèbvre (1997) pour étudier la façon dont le capitalisme contemporain s’infiltre dans tous les aspects de la vie quotidienne. Elle reprend sa définition de la vie quotidienne comme l’ensemble des activités humaines qui ne sont pas spécialisées. Le développement du capitalisme et les luttes ouvrières ont permis d’améliorer les conditions de vie et de travail et de libérer un espace pour le loisir. La domination par la contrainte n’est plus suffisante. Alors s’amorce, selon l’autrice, la colonisation progressive de la vie quotidienne par le capitalisme. La publicité et les techniques de marketing de plus en plus sophistiquées seront l’instrument de la manipulation des besoins et des désirs à des fins économiques. L’arrivée des plateformes élargit le domaine de la manipulation de masse. Les algorithmes permettent de développer une technologie de la persuasion, une ingénierie comportementale, qui manipule les circuits de la récompense des usagères et usagers pour les retenir le plus longtemps possible en ligne afin de recueillir les données qui deviennent des marchandises vendues pour des publicités ciblées. La dépendance laisse des traces psychologiques destructrices. La logique économique des plateformes exige une manipulation des désirs et du besoin d’autonomie des individus et des collectivités. Elles génèrent un sentiment d’impuissance qui entrave la capacité d’agir collectivement contre l’emprise du capitalisme sur la vie elle-même.
La façon de se concevoir soi-même et de concevoir le monde, qui nous semble spontanée, n’échappe pas à l’emprise du capitalisme. L’uniformisation des sociétés et l’hyperconsommation constituent, selon l’autrice, « la matrice de la conscience contemporaine ». Le règne du marché est incontesté, tous les États s’y soumettent. La signification subjective de la consommation change. Le marketing expérientiel nous vend du sens plus que des biens, la marchandise devient émotionnelle, la recherche du bonheur individuel, un bonheur formaté pour les exigences du marché.
Cet environnement économique et social a des effets délétères sur la subjectivité et la personnalité humaine. Le système valorise l’autonomie, mais il provoque en fait un appauvrissement de notre expérience de soi et du monde. Le consommateur, ou la consommatrice, est invité à gérer sa vie de façon à optimiser ses compétences et son bien-être. Une foule d’applications et l’industrie du psy proposent toutes sortes de moyens pour gérer son anxiété ou sa sexualité. Mais cette attitude bienveillante envers les individus vise surtout à améliorer la productivité. L’aspiration à l’autonomie, à l’expression de sa créativité et de son individualité est détournée pour se conformer à la logique du marché. Selon Stéphanie Roza, l’aliénation marchande dépossède les citoyens et citoyennes de leur vie, de leur humanité. L’individu narcissique semble le mieux adapté au capitalisme tardif. Le capitalisme a ouvert d’immenses possibilités d’action individuelle et collective, mais son fonctionnement même en empêche la réalisation.
La société contemporaine n’est pas le cauchemar que certains dépeignent, mais elle provoque des souffrances à la fois matérielles et psychiques. L’autrice pense qu’on a sous-estimé l’importance du manque de démocratie comme source des pathologies contemporaines. Pour changer les choses, il est essentiel de démocratiser le travail pour se réapproprier le progrès technique, mais il faut aussi démocratiser la vie quotidienne. Roza laisse en suspens la question des moyens concrets pour créer des organisations qui refusent de manipuler les masses à leur profit et qui décident de prendre au sérieux l’émancipation humaine. Pourtant, il s’agit d’un défi que l’humanité devra relever un jour, si elle ne veut pas disparaitre.
Par Pierre Leduc, professeur de philosophie retraité du cégep de Jonquière

Note de lecture – Un pays selon mon cœur. Entretiens avec Éthel Groffier

Un pays selon mon cœur. Entretiens avec Éthel Groffier
Georges Leroux, Montréal, Somme Toute, 2024
On sort de cette lecture éprise d’une grande humilité – même si, de ses propres mots, elle se méfie de ce sentiment, lorsqu’exposé. Je prends ce risque, car Éthel Groffier aime aussi l’audace.
Humilité, car on peut facilement être dépassé par les nombreuses références qui vont de la littérature, de l’histoire, de l’histoire de l’art, du droit international, de la philosophie, du Code civil au langage opaque des différentes grandes bibliothèques et des livres rares et anciens. Une richesse du propos que je ne prétends pas avoir assimilé complètement, mais pour paraphraser Bernard Émond dans la Leçon de scénarisation : « On m’a appris que les choses compliquées étaient importantes ».
D’entrée de jeu, avançons cette idée que le pays du Québec comme concept de souveraineté est en filigrane de l’ouvrage. Il n’est pas frontal au livre comme pourrait le supposer le titre de l’ouvrage. Le véritable pays de cette autrice venue de Belgique, qui a vécu les affres de la Seconde Guerre mondiale dès l’âge de cinq ans, Dunkerke, les déplacements, la grisaille, la faim (le pain gris et gluant), l’incertitude… Le véritable pays de cette femme où les livres ont été une terre fertile contre l’ennui, la bêtise des hommes, les dogmes religieux de sa mère… Le véritable pays de cette grande dame d’histoire, de droit international, première professeure embauchée à temps plein en droit à l’Université McGill, est la liberté de penser. Là est son pays. Dans l’exigence que cela suppose.
Pourquoi écrire ce livre ? « Il m’a pris l’envie très simplement de retracer mon parcours et de le faire avec un peu de rigueur. Qu’ai-je appris de la guerre, de l’immigration, de l’amitié, de l’indomptable bêtise humaine, de l’incroyable beauté du monde, en quoi les livres m’ont-ils aidée à survivre? » (p. 16)
Après ses études en droit international, elle décrochera un premier boulot alimentaire dans une usine de distribution du lait. Elle y prendra le parti des ouvriers et ouvrières lors de la grève pour de meilleures conditions de travail. Elle qui sera professeure plus tard dira : « Sans adopter les théories du président Mao, je me demande si un stage en usine ne serait pas salutaire à nos étudiants super choyés par les universités, mettant à leur disposition des “espaces de sécurité” où réfugier leur sensibilité blessée par des sujets qui fâchent » (p. 78). Éthel Groffier ne mâche pas ses mots contre la moralité quasi sectaire de ce qui peut être dit ou tu.
Elle a travaillé sept ans à l’Organisation internationale du travail (OIT). Elle avait pour mandat de décortiquer les menaces langagières de l’Est, en pleine guerre froide. Elle y apprendra l’importance de s’informer de l’opinion de l’adversaire… « et (aujourd’hui) je me surprends toujours d’entendre des personnes pourtant intelligentes déclarer : Ah non, je ne vais pas lire le livre d’un tel. Il est de droite (ou de gauche) ». Encore ici, il faut y voir l’importance de la pluralité de penser, de la négation de l’enfermement et du prosélytisme comme étant son véritable pays.
Notons ce beau parallèle : Raymond Klibansky, philosophe engagé dans les valeurs humanistes et universalistes, ce mari et amour qu’elle rencontrera plus tard, a travaillé en Angleterre lors de la Seconde Guerre mondiale à débusquer l’ennemi nazi à travers l’humeur de la langue allemande. Ces deux-là étaient visiblement destinés à se rencontrer.
Arrivée au Canada pour faire sa thèse de doctorat, d’abord à Ottawa ; elle y décrochera un boulot pour traduire les différentes conventions internationales pour la réalité intérieure des provinces. Elle comprendra rapidement comment ce pays peut être dysfonctionnel par son territoire immense et ses réalités distinctes. « Pourquoi ne pas reconnaître que le Québec était une société distincte, cela me paraissait tellement visible ? En quoi cette simple constatation pouvait-elle déranger, en particulier Pierre Trudeau qui avait fait une campagne féroce contre cette idée ? » (p. 116)
Éthel Groffier aimera Montréal, elle pour qui l’écriture est un besoin et un art. Dans le passage suivant, on y sent toute la douceur de l’apatride : « Montréal est une ville fluviale sans insularité. La ville vit, vibre, respire large par les poumons du fleuve et de la montagne. La liberté s’y nourrit d’espace physique et moral. Il y a toujours un ailleurs, au-delà du fleuve, au-delà de la forêt, au bout de la route. On peut espérer un mieux dans une société sans caste, où la mobilité sociale est non seulement possible, mais encouragée » (p. 102).
L’autrice, poursuivant sa thèse à McGill, travaillera à réviser le Code civil au Québec et participera de par ses travaux et enseignements à rendre les femmes égales en droits.
Une fois sa thèse terminée, elle enseignera le droit à McGill, la liberté contre le joug des diktats. Elle sera fidèle à elle-même en parlant d’un âge d’or de l’enseignement où on avait du temps pour réfléchir, du temps pour se ressourcer, pour lire, pour avoir des projets intellectuels à soi ; contre l’impératif marchand de tant d’articles à produire et de répondre illico aux courriels et textos de ce monde contemporain où la satisfaction de la clientèle étudiante devient une exigence.
À travers ses écrits, Éthel Groffier défendra l’esprit des Lumières, les valeurs des droits de la personne et de la démocratie libérale. Sans enfermer Voltaire, par exemple, dans les défauts moraux du présent, elle dira : « Il a été libérateur de la rouille des siècles » (p. 228). « La liberté n’est pas une marque de yogourt, disait l’autre[1] ».
Autour de la souveraineté du Québec, une tension parcourt l’ouvrage. Éthel Groffier a voté NON au référendum de 1995, et ce, malgré « l’importance d’un certain idéal d’universalité dans ce qu’elle aura découvert au Québec : non seulement une richesse sociale et politique qui n’aura pas cessé de nourrir sa réflexion sur la différence et l’appropriation, mais surtout aussi peut-être une histoire dans laquelle la requête de souveraineté continuera de jouer un grand rôle » (Georges Leroux, en ouverture, p. 14).
L’autrice débutera le récit avec un : « On ne naît pas québécois, on le devient », à la Simone de Beauvoir reprise par Marco Micone.
« Il faut apprendre l’histoire du Québec, écouter les chansons qui le font vibrer, goûter la saveur de son parler, admirer la beauté de son territoire, savourer ce qui en fait un lieu unique pour, enfin, le faire sien » (p. 15). Il faudra, dira-t-elle, comprendre les idéaux, souverainistes comme fédéralistes.
Les souverainistes ne l’auront pas convaincue d’un projet suffisamment audacieux pour tenter l’expérience de la souveraineté. Elle y liste, à titre d’arguments, les exigences du capitalisme mondialisé, les alliances économiques dont fait partie le Canada, la crise climatique qui nécessitera plus de liant que de séparation.
Cette femme assoiffée de liberté qui a côtoyé des auteurs et autrices et de grands salons européens et canadiens – aux côtés de Charles Taylor notamment – est-elle allée au bout de sa quête ? Comprendrait-elle que la sauvegarde de cette unicité française en Amérique du Nord n’est pas un caprice ni une crispation, mais une exigence viscérale ? Exactement comme le regard bienveillant qu’elle pose sur les Premières Nations ?
« Ma sensibilité va à l’indépendance du Québec ; mon intellect voit les obstacles. Je suis souverainiste de cœur… » (p. 176).
Et moi, qui vous résume, je le suis toute entière, de cœur et de tête. Comme une bûcheronne des temps modernes, je souhaite que nous arrêtions de vivre ce pays de l’imaginaire et que l’on bâtisse quelque chose qui nous rassemble et nous ressemble. Une oasis sociale-démocrate. Une alternative singulière de justice et de beauté.
Par Judith Trudeau, professeure de science politique au Collège Lionel-Groulx
- Pierre Falardeau. ↑

Note de lecture – Ordures ! Journal d’un vidangeur

Ordures ! Journal d’un vidangeur
Simon Paré-Poupart, Montréal, Lux Éditeur, 2024
Simon Paré-Poupart travaille comme vidangeur à temps partiel depuis qu’il a 18 ans. Se décrivant lui-même comme un « mercenaire des vidanges » (p. 48), il a navigué entre les brokers – sous-traitants œuvrant pour les conglomérats qui dominent maintenant le marché des ordures – et a côtoyé des vidangeurs et des vidangeuses de toute la grande région de Montréal.
Le livre Ordures ! est le journal de ce vidangeur plutôt atypique qui nous livre le portrait de nombreux vidangeurs typiques, mais aussi celui des contribuables et des bourgeois qui les traitent comme des moins que rien. On y retrouve les observations d’un intellectuel organique au milieu des « matières résiduelles » et une certaine analyse de classe qui vient avec. Paré-Poupart cite d’ailleurs l’Établi de Robert Linhart comme une inspiration[1]. Son livre est aussi criblé de digressions sur des phénomènes généraux du monde des ordures, comme les tares de notre système de recyclage, l’histoire de la collecte des déchets ou la surconsommation.
Pris dans son ensemble, Ordures ! est le récit d’une mise à l’écart des vidangeurs par la petite bourgeoisie et la bourgeoisie et des effets produits par cette marginalisation sur ces ouvriers comme sur notre société. C’est aussi une attaque contre ce dédain que l’idéologie dominante manifeste vis-à-vis « ceux et celles qui travaillent dans l’ombre pour que nos vies soient meilleures » (p. 70). Paré-Poupart et plusieurs de ses collègues sont fiers de leur métier ; il s’avère donc incontournable que l’auteur critique le mépris porté envers eux par beaucoup de ses concitoyens et concitoyennes.
La collecte des ordures est une activité fort éreintante et dangereuse, une activité qu’on réserve généralement à des « marginaux-déviants » (p. 97), comme les appelle l’auteur. Lorsqu’il décrit ses collègues, on sent une certaine influence de Zola, si ce n’est que le grand auteur naturaliste a dû inventer Étienne Lantier et Gervaise Macquart, alors qu’ici Racette, Spandex ou Ti-Chris n’ont rien de fictif.
Les conditions de travail ridicules, aggravées par l’inexistence de syndicat et la domination des trusts et du crime organisé sur l’industrie, font que les vidangeurs sont souvent recrutés parmi les « poqués », parmi ce que Marx appelait péjorativement le lumpenprolétariat. On retrouve d’anciens motards, des itinérants, des jeunes d’Hochelaga à Montréal qui ont commencé comme vidangeur à 14 ans, d’autres qui fuient la police quand ils la voient se pointer le bout du nez, « [d]es édentés, des tatoués, des pas-propres dont le linge semble sortir tout droit des poubelles » (p. 28). Au centre des multiples problèmes de cette « pépinière de voleurs et de criminels de toute espèce[2] », on retrouve la drogue et l’alcool. Selon Paré-Poupart, la « figure du père alcoolique ou toxicomane est fréquente chez les vidangeurs » (p. 17) et plusieurs histoires de l’origine des éboueurs, dont celle de l’auteur, sont liées à des problèmes familiaux amplifiés par la dépendance. Dur encore de ne pas voir un parallèle avec Zola, qui faisait de l’alcoolisme une tare génétique destinant les familles affectées à sombrer dans la déchéance du travail ouvrier, mais dans Ordures !, on ne tombe pas dans le déterminisme social vulgaire d’un naturaliste du XIXe siècle.
L’auteur soutient en effet que « vidanges, c’est souvent une affaire de famille » (p. 35), pour des raisons de reproduction sociale, pour des raisons de classe. « [L]es Noirs, les Latinos ou la white trash qui ramassent les déchets, ce sont essentiellement des pauvres » (p. 97), exprime-t-il. Le chapitre Les petits enfants et les camions traite spécifiquement de ce sujet et montre qu’il y a une réalité matérielle qui pousse vers cette reproduction intrafamiliale du métier de vidangeur. Il donne l’exemple de Stéphane, un chauffeur qui se bat « contre les puissantes forces qui attach[en]t sa famille au monde ouvrier » (p. 36) et qui craint que si son fils ramasse des poubelles l’été, il ne puisse s’élever socialement.
Cette sous-classe de prolétaires maganés, et peut-être est-ce là le leitmotiv du livre, est mise au rancart par le reste de la société autant que faire se peut. L’auteur le dit bien : une benne à ordures, ça ne « fitte pas dans le décor bucolique d’une banlieue » (p. 100). Et les gens plus aisés, petits-bourgeois comme grands bourgeois, n’ont d’égards pour le personnel venant avec le camion de vidanges qu’une fois par année au grand maximum, à Noël. Le cycle des déchets finit par devenir invisible tandis qu’on transforme en capital cette réalité humaine et qu’on ferme les yeux sur le monde matériel, trop crasseux.
La collecte du recyclage fait encore plus transparaitre cette contradiction. Le travail de « gestion des matières résiduelles » est, pour les classes dominantes, une « illusion que la planète est sauve » (p. 71) alors que le vidangeur, sur le terrain, sait très bien qu’on finit par jeter les matières recyclables à travers toutes les autres immondices que les conglomérats vendront à des spécialistes du « recyclage » en Asie du Sud-Est. Paré-Poupart se désole ainsi que certains des déchets qu’il a ramassés pour la compagnie mafieuse Ricova se sont retrouvés en Inde. Le regard détourné autant que faire se peut des ordures et des gens qui les ramassent, nos décideurs et leur classe ne peuvent que différer les problèmes liés aux déchets sans les régler. Le livre de Paré-Poupart fait un excellent travail dans la direction inverse, c’est-à-dire celle de montrer la réalité concrète et humaine de cette industrie capitaliste.
Par André-Philippe Doré, boulanger et administrateur de la Ligue 33
- 1. L’Établi est un récit autobiographique de Robert Linhart paru en 1978 aux Éditions de minuit, qui raconte l’expérience de son auteur en tant qu’ouvrier dans l’usine Citroën à Paris en 1968. Dans une entrevue à Daniel Chrétien (« Titulaire d’une maîtrise et vidangeur », L’actualité, 11 septembre 2024), Paré-Poupart, fait étrange, décrit Linhart et ses camarades comme étant des « sociologues français » alors qu’il s’agissait de maoïstes voulant mener la lutte armée dans les usines. ↑
- 2. Karl Marx, Les luttes de classes en France, 1848-1850, Chicoutimi, Classiques des sciences sociales, p. 34. ↑

Capital contre climat : une contribution écoféministe

Ce texte a été présenté à la Grande conférence Climat contre capital : quelles issues possibles ? le 30 mai 2025 dans le cadre du colloque La Grande Transition 2025 à Montréal.
Tout d’abord, je veux dire que ce sujet, Climat contre capital, dans la période actuelle, a pris une acuité incroyable, en même temps qu’il est dramatiquement mis de côté. Je veux dire aussi que je parle d’un point de vue de militante, militante féministe et écoféministe, et non d’universitaire.
C’est un capital pur et dur qui a pris le pouvoir, et qui cherche à s’imposer au monde entier. Il a mis à sa tête un magnat qui s’est proclamé roi et maitre des nations. Magnus 1er détruit méthodiquement des politiques et des acquis – enfin ce que nombre d’entre nous avons pris pour des acquis, souvent chèrement gagnés, de démocratie, de justice, d’environnement.
Nous sommes bousculéꞏes, et pour le moment presque impuissantꞏes devant ce qui arrive. Oui, il y a des tentatives de résistance, mais en réalité, aujourd’hui, les destructions sont à peine retardées dans certains domaines alors que partout où la royauté avance, les dégâts s’accumulent et leurs effets à long terme sont déclenchés alors même que nous voudrions revenir en arrière.
Ce Magnus et son insolente et richissime oligarchie détruisent l’environnement. L’environnement total, dans ses trois dimensions habituelles et dans la quatrième : le changement climatique, la perte de biodiversité, la pollution ET la société humaine. Faut-il le dire et le redire, la société est une dimension incontournable de notre environnement, un facteur de plus en plus important dans l’écologie de la planète : autant dans la destruction de son équilibre que dans la réparation qu’on peut tenter d’y apporter. Il faut penser société dès qu’on parle d’écologie : l’anthropocène est une description pertinente, comme les termes de capitalocène et d’androcène.
Les connexions
Le premier point que je veux établir, ce sont les connexions. Tout est relié. C’est le sens même de l’écologie, comprendre et respecter les liaisons de tout ce qui existe. C’est vrai biologiquement, et c’est vrai socialement, c’est vrai dans le croisement de la nature et de la culture, dans la rencontre du biologique et de l’artefact.
J’en fais mon point de départ. Nos luttes environnementales ne doivent plus séparer ce qui serait « la nature » et ce qui est social. En bref, le déséquilibre écologique vient de l’action humaine, toutes les dégradations écologiques impactent des êtres humains à des degrés divers, aucune transition écologique positive ne peut s’effectuer sans l’implication consciente et consentante des groupes humains qui sont concernés.
Si, comme je le pense, l’implication volontaire des sociétés humaines est nécessaire à une action écologiquement bienfaisante, on est donc devant un énorme problème. Car le Capital, celui-là même qui détruit, occupe tout l’horizon. Celui de la vie réelle et celui de la vie rêvée.
La vie réelle : la subsistance et le soin
Le Capital occupe l’horizon de la vie réelle, car il a réussi à marchandiser presque tout ce qui fait la subsistance quotidienne : aliments, vêtements, logements, loisirs, mobilité, soins de santé, instruction. On dirait bien qu’il nous a dépouilléꞏes de toutes nos habiletés de base à fabriquer les objets de notre subsistance pour nous restreindre à les acheter au prix de notre travail rémunéré, un travail qui n’a le plus souvent aucun rapport avec notre vie à nous. L’argent médiatise notre rapport aux ressources vitales, et nous sommes écarteléꞏes entre deux sphères étrangères l’une à l’autre : d’un côté notre activité rémunératrice, de l’autre notre vie propre. Toutes celles et ceux qui ne « gagnent » pas l’argent de leur subsistance sont déconsidéréꞏes, tombent en carence grave ou en dépendance de l’État pourvoyeur.
Cette description omet les activités de soin qui pourtant forment le tissu nourricier de notre vie. Préparer les aliments, s’occuper des vêtements, nettoyer les personnes, entretenir le logement, répondre aux enfants – et d’abord les avoir ces enfants, les porter neuf mois, en accoucher –, parler avec les autres, aimer, s’opposer, soigner les bobos et les invalidités, entretenir des amitiés, fleurir le bout de terrain dehors, participer au comité d’école, avoir une vie sexuelle se soucier de l’état du monde, prendre soin de ce que les « Gazas » et les persécutions politiques font à notre santé mentale personnelle et collective… Tout ce qui n’est pas marchandisable, ou pas encore complètement marchandisé, mais qui est partie intégrante de notre subsistance, est mis de côté.
En fait, oui, il y a un rapport entre notre activité rémunératrice et notre vie propre : c’est celui du temps, du rythme, de l’énergie requise. Pour beaucoup d’entre nous, le travail rémunéré prend un temps considérable et, surtout, nous impose un rythme accéléré et un stress qui viennent sérieusement restreindre notre vie personnelle. Après le travail, que nous reste-t-il comme disponibilité pour les soins ?
La vie rêvée : une vie colonisée
Indisponibles, on s’évade alors dans la vie rêvée, elle aussi occupée par le Capital. Car que sont devenus nos rêves ? Précédés par les écrans, peuplés par la publicité omniprésente, les voilà désormais rêves de consommation : meubles, voyages, autos, spectacles, disponibles en un clic sur nos écrans, modelés par la vue des gens riches et célèbres ou des influenceurs et influenceuses, suggérés par une intelligence artificielle qui nous entraine dans des univers inouïs et tellement alléchants, brouillant la ligne entre le réel et le « transmachinal » – cet au-delà du réel que crée la machine dite intelligente.
Quand non seulement la vie réelle mais aussi la vie rêvée sont colonisées par le Capital, alors le soin de l’environnement et les luttes environnementales semblent impossibles.
Y a-t-il des issues ? Où chercher la motivation ?
Pour attirer les gens dans des actions environnementales positives, quels sont donc nos incitatifs ? Le premier est sans doute la perception des désastres déjà en cours et l’appréhension devant le futur qui se dessine. Or, le Capital a une puissante réponse : la transition technologique. Applaudissez, mesdames et messieurs, la technologie va nous sortir de ce mauvais pas. Les Elon Musk de la terre sont là pour nous montrer la voie de l’avenir, multiplier les énergies non polluantes, virtualiser nos activités, construire des cités dans les étoiles. On peut continuer à vivre comme on vit, nul besoin de sacrifier telle ou telle habitude chère, la technologie évolue et va tout régler. Allez, circulez, consommez !
Pourquoi parler encore des abeilles et autres pollinisateurs en voie de raréfaction ? Pourquoi se faire des peurs avec les océans de plastique ? Redouter les feux de forêt et les sécheresses ? Lutter pour des milieux humides dans nos villes ? Le Capital n’en a que faire, il a vite fait de nous en distraire et d’amener notre attention ailleurs.
Un autre incitatif possible pour les luttes serait le bien-être quotidien : mais en avons-nous encore une idée le moindrement écologique ? L’alimentation saine, les transports sobres, les produits « naturels » ne font pas le poids devant les incitatifs quotidiens de nourriture hypertransformée, les injonctions à la beauté et à la vitesse, ou les contraintes de temps et les transports publics insatisfaisants. Les décisions de changement de mode de vie, personnelles ou collectives, demandent de l’attention, du temps et même de l’argent, alors que nos vies sont déjà hypothéquées par le stress et la consommation tous azimuts.
Il est clair que le Capital a non seulement le pouvoir économique sur la production, mais aussi le contrôle culturel sur la consommation. Nos besoins, nos désirs, nos esprits sont colonisés.
L’aspiration au bien-être quotidien ne tient pas la route devant la tâche énorme qui est devant nous, celle de renverser la vapeur d’un système économique puissant qui échappe à tout contrôle. Il faut même reconnaitre que ce système a lui-même pris le contrôle des leviers qu’on croyait pouvoir utiliser pour lui imposer des limites : le politique, le judiciaire, l’information, la démocratie.
Mais sans doute est-ce la victoire même de l’adversaire qui nous indique la motivation qui fonctionne : c’est la colère et la révolte des populations devant les pertes, les désillusions, le bouleversement de nos modes de vie et même de notre monde. Pertes d’emploi, déqualifications, endettement, transformations des quartiers urbains et des milieux de vie, retrait des interactions humaines dans un tas de domaines, sentiment de pauvreté devant une vie où l’accessoire est devenu coûteusement nécessaire, écarts de richesse grandissants, catastrophes et destructions ici et là… La colère gronde un peu partout, dans les villes et les campagnes, chez les artistes et chez les agriculteurs, chez les jeunes et chez les moins jeunes. La mondialisation et la technologie ont fait miroiter une belle vie facile. Les vingt dernières années ont produit le contraire. Les droites et les extrêmes droites ont su saisir ces désillusions et les transformer en révolte contre les pouvoirs démocratiques. Les gauches n’auraient-elles pas une réflexion à mener au ras des pâquerettes sur leurs stratégies et leur discours ?
Soyons réalistes : les luttes pour le climat sont perçues au mieux comme secondaires par rapport à l’économie, sinon même comme nuisibles, trop dispendieuses, au pire comme créées de toutes pièces pour manipuler le peuple.
Une mobilisation à alimenter
Pourtant, on peut constater que l’environnement est mobilisateur dans l’opinion publique. Il a mobilisé de très grandes foules dans la rue. Il réunit des militantes et militants au-delà du silo de leur « cause principale ». Autour du climat existe un état d’alerte qui est alimenté par des réseaux bien organisés et documentés. En dehors des milieux climatosceptiques, tout le monde est d’accord – en principe – pour réduire les gaz à effet de serre, protéger la biodiversité, récupérer, recréer des liens sociaux. Cet accord ne diminue pas, au contraire : les changements climatiques provoquent de plus en plus de catastrophes à toute échelle, constamment médiatisées, ce qui entretient l’actualité et l’intérêt pour le sujet. D’une façon ou d’une autre, une immense partie de la population se sent concernée par la crise environnementale.
Ici, je reviens aux connexions. Il me semble qu’on pourrait donner à voir – en commençant par le voir nous-mêmes – comment les bouleversements qui affectent le climat, la nature et la société sont reliés entre eux. Et cela, en partant des insatisfactions et de la colère dont on vient de parler, dans des réflexions accessibles, avec un langage non spécialisé, mais en chargeant les mots d’un contenu intense, en apportant des connaissances qui intéressent les gens et en montrant les connexions entre ces crises.
Un exemple d’éveil aux connexions
Je voudrais donner un exemple personnel d’éveil aux connexions : moi qui viens du mouvement féministe, c’est en creusant la question féministe du travail invisible et du travail de soin non rémunéré que j’ai compris l’accointance du capitalisme avec le patriarcat – ou la domination masculine. L’exploitation éhontée des ouvriers a rendu nécessaire d’assigner les femmes au travail domestique pour reproduire la classe ouvrière, c’est-à-dire pour faire des bébés viables et pour nourrir les hommes et en prendre soin quand ils revenaient éreintés du travail. En allant plus loin, j’ai appris par les écrits de Silvia Federici comment Marx a eu un point aveugle dans sa théorie des classes sociales. Il a tout simplement situé les femmes dans la même classe sociale que leurs hommes, alors que leur place par rapport à la production est radicalement différente de celle des hommes. Car en fait, les femmes assurent plutôt la re-production, sur laquelle repose le système de production.
Cette réflexion est synthétisée dans l’image de l’iceberg développée par les féministes : la partie visible du fonctionnement social, l’économie marchande, repose en réalité sur une énorme masse invisible sans laquelle elle ne pourrait pas fonctionner : ce sont les soins gratuits aux personnes, fournis par les femmes et les groupes assimilés. Plus profondément, le tout est porté par la nature, qui fournit la base de toute subsistance. Sans les soins, sans la nature, l’économie coule. C’est ce que signifie l’iceberg.
S’il est difficile de saisir le capitalisme à l’œuvre, c’est la réflexion sur l’écologie qui m’a amenée à comprendre profondément sa dynamique de croissance, jusque-là demeurée théorique pour moi. De même, les liens du capitalisme avec le colonialisme et le racisme sont devenus clairs à partir de la question de la croissance et de l’expansion des marchés.
Tout le monde peut ainsi apprendre à voir les connexions, pourvu qu’on parte des situations vécues, des dominations refusées, des espoirs agissants.
La source féministe
Ici, je propose de nous alimenter à une source féministe qui s’est conjuguée à l’écologie, une source écoféministe.
Le féminisme qui consiste à rechercher l’égalité de droits entre les femmes et les hommes, ou entre les genres, a heurté sa limite : plusieurs féministes ont compris que si les droits sont une voie vers la vie bonne, cette voie est sans issue dans le monde actuel. Changeons donc le monde, disent-elles, construisons un monde qui ne repose pas sur des dominations. Les patriarcats, les oligarchies, le capitalisme colonisateur, les racismes, nous voulons les détrôner.
Nous – et maintenant je parle de nous, les femmes –, nous nous inspirons, dans les Amériques du moins, du buen vivir autochtone, de la connexion à la nature porteuse, au territoire qui fournit la subsistance, aux origines et aux sept générations à venir. À travers le foisonnement technologique, nous cherchons à recréer les liens de base entre les humains, avec les autres vivants et avec la planète.
Nous avons travaillé fort depuis plus de 150 ans à découvrir les racines des violences qui s’exercent contre nous. À valoriser ce que nous savions faire de plus précieux et que la société pourtant méprisait : prendre soin de la vie. Assignées à ce travail par le pouvoir capitaliste et patriarcal, nous avons développé, en le pratiquant, des savoir-faire, des capacités d’attention et de perception, des sensibilités jouissantes qu’il nous importe de mettre en œuvre dans une vision « dé-capitalismée ». Depuis que nous ouvrons d’autres portes, nous avons aussi acquis les savoirs, les qualités professionnelles et les habiletés politiques dont nous avions été écartées. Et nous avons bouleversé les relations de genre, refusant l’infériorité, apportant notre force, créant de nouvelles formes de rencontre.
Même si nous avons accédé à tous les domaines de la vie collective, nous sommes encore les principales responsables de la reproduction humaine et de la vie domestique. C’est donc partout que nous recevons de plein fouet les impacts des destructions environnementales. Au sud et au nord de la planète, nous constatons les dommages, réparons les pots cassés dans la vie quotidienne et tâchons d’inventer des façons viables d’assurer la subsistance humaine, en joignant le soin des gens et de la planète. Les femmes ont conjugué leur prise d’autonomie et leur action écologique depuis des dizaines d’années, ce qui touche l’ensemble de leur vie pratique et affective. Elles s’impliquent dans des actions et des mouvements écologiques dont la plupart sont en relation avec la base de la vie, la subsistance. Elles sont impliquées politiquement et scientifiquement.
Sommes-nous loin de la colère et de la révolte que j’ai nommées plus haut comme motivation pour l’action ? Au contraire : ne nous méprenons pas sur les formes que prend la colère. Elle brise des chaines et transforme le monde autour d’elle, mais lorsque son but est d’améliorer la vie, elle ne prend pas les armes, elle agit, elle invente, elle prend soin différemment.
Pour terminer
En conclusion, plusieurs formes de résistances et de luttes écologiques sont nécessaires pour faire face à la crise qui sévit et qui s’aggrave. Ceci est un plaidoyer pour l’une d’entre elles, un écoféminisme construit par l’expérience trop longtemps ignorée d’une moitié de l’humanité. Cet écoféminisme invite à mettre au centre de nos visées écologiques le souci d’une vie humaine riche de connexions avec les vivants et avec la planète qui les porte.
Et en terminant, merci à toutes les militantes qui m’ont guidée et inspirée dans les dernières décennies.
Merci à toutes les autrices féministes qui ont su nourrir ma réflexion par des écrits où l’expérience donne naissance à de la théorie qui en retour vient éclairer l’action. Je n’en mentionnerai ici que trois, celles qui ont formulé la perspective de la subsistance que j’adopte : Maria Mies, Vandana Shiva et Veronika Bennholdt, par leurs livres Écoféminisme et La subsistance[1].
Par Élisabeth Germain, féministe, écoféministe et sociologue. Elle est membre du comité Femmes et écologie du Regroupement des groupes de femmes de la Capitale-Nationale et du Collectif écosocialiste et écoféministe de Québec solidaire.
- Maria Mies et Vandana Shiva, Écoféminisme, Paris, L’Harmattan, 1998, traduction de Ecofeminism, Londres, Zed Books, 1993 ; Maria Mies et Veronika Bennholdt, La subsistance. Une perspective écoféministe, Paris, Éd. La Lenteur, 2022, traduction de l’édition anglaise de 1999. La version originale allemande est sortie en 1997.
Ces deux ouvrages restent extraordinairement pertinents. Le premier comporte plus de critique épistémologique, le langage du second est peut-être plus relié à l’action pour des lectrices et lecteurs aujourd’hui, mais les deux déploient les mêmes enjeux critiques qui éclairent étonnamment la conjoncture actuelle. ↑

100 ans de domination d’Alcan-Rio Tinto au Saguenay-Lac-Saint-Jean

L’histoire du Saguenay-Lac-Saint-Jean est d’abord marquée par le peuplement de colons, le commerce de la fourrure, l’agriculture, la coupe de bois, puis par la domination de quelques grandes entreprises qui ont exploité, et qui exploitent encore, nos richesses naturelles, notamment dans les domaines du bois et de l’aluminium, au détriment de l’environnement et du bien-être de la population, avec la complicité active des gouvernements.
Faire le bilan de 100 ans d’exploitation par la compagnie Alcan-Rio Tinto sur le territoire du Saguenay-Lac-Saint-Jean est une entreprise colossale, nous n’avons pas la prétention de viser cet objectif. Nous nous limiterons à donner quelques exemples frappants d’une domination sans scrupule, applaudie par ceux et celles qui devraient plutôt se tenir debout pour défendre le bien commun et nos richesses collectives[1].
Le modus operandi est celui-ci : on planifie une action en catimini avec la complicité d’élu·e·s locaux et de l’Assemblée nationale[2], puis on place la population devant le fait accompli en faisant miroiter des emplois et du progrès, et on légalise ensuite l’opération, rétroactivement s’il le faut, tout en ostracisant les opposants et opposantes. C’est ce qu’on a fait lors de la tragédie du lac Saint-Jean en 1926.
La tragédie du lac Saint-Jean
Le Piékouagami[3] avait déjà été rebaptisé lac Saint-Jean par Jean de Quen en 1647, en hommage à son saint patron, Jean le Baptiste. Il perdra plus tard son statut de lac pour devenir un réservoir le 24 juin 1926. La compagnie Alcan, en implantation dans la région, avait besoin d’électricité pour sa nouvelle usine d’Arvida (aujourd’hui incorporée à la ville de Saguenay). Elle avait acquis quelque temps auparavant la compagnie Duke-Price Power, qui avait fait construire cinq barrages avec évacuateur de crue à la sortie du lac, dont celui de l’Isle-Maligne, qui a la capacité de réguler le niveau du lac. Cette transaction incluait les droits hydrauliques et la gestion de l’élévation du lac Saint-Jean et d’une partie de la rivière Saguenay entre Alma et Shipshaw.
Ayant reçu dans le secret le plus total l’autorisation du gouvernement libéral de Louis-Alexandre Taschereau de hausser le niveau du lac à la cote maximale de 17,5 pieds, soit 10 pieds de plus que le niveau moyen, Alcan ne procéda à aucune entente d’expropriation avant la fermeture des vannes en 1926. C’est sans avertissement, et ironiquement le jour de la fête de la Saint-Jean-Baptiste, que la compagnie ferma les vannes du barrage de l’Isle-Maligne et laissa l’eau monter tout bonnement. Les quelque 940 cultivateurs aux abords du lac, qui s’enorgueillissaient d’avoir les plus belles terres au monde, si bien que l’on désignait la région comme le « grenier du Québec » – ce dont pouvaient témoigner les nombreux prix agricoles qu’ils remportaient chaque année à l’échelle nationale – perdirent subitement en tout ou en partie leurs terres, soit 60 000 acres. Onésime Tremblay, qui prit la tête du mouvement du Comité de défense, perdit lui-même la plus belle forêt de 150 acres d’ormes de la région, dans le secteur de Couchepagane[4] (secteur de la Belle Rivière formant le Grand Marais), à Saint-Jérôme (aujourd’hui Métabetchouane et Saint-Gédéon). Cette tragédie humaine, commise sans avertissement et dans l’illégalité, inonda de nombreuses villes et villages, affectant sérieusement leur fonctionnement, jusqu’à amener leur fermeture et disparition, comme celle du village de Bien-Heureuse-Jeanne-D’arc. C’est en mars 1927 que le premier ministre Taschereau fit adopter une loi expropriant les sinistrés et ordonnant leur indemnisation par l’intermédiaire d’une commission chargée d’en fixer le montant sans droit d’appel[5]. Cette loi légalisera rétroactivement ce qui avait été fait illégalement un an plus tôt, avec l’appui des conseils municipaux de Chicoutimi, d’Alma et d’autres élus régionaux.
Onésime Tremblay, ayant dépensé une fortune en frais juridiques pour défendre sa cause et celle des cultivateurs, a finalement tout perdu : sa ferme, sa maison, ses animaux. La compagnie, sachant qu’elle avait été ignoble envers lui – elle lui avait offert 7 000 $ pour sa terre qu’il évaluait à 168 000 $ – a offert à le compenser plusieurs années plus tard : elle lui offrit un chèque en blanc où il aurait pu inscrire le montant qu’il voulait. Onésime Tremblay refusa catégoriquement ce chèque en blanc de la compagnie, car ce qu’il désirait plus que tout était de récupérer sa terre et sa forêt : « Aussi longtemps que ceux qui sont chargés de protéger la société seront complices des compagnies qui veulent tout dominer chez nous, il n’y aura pas de changement. Mais en attendant, nous, nous lutterons jusqu’au bout. Ces choses-là devraient être connues du public[6] ».
Cette tragédie a marqué les débuts de la relation entre Alcan, et, plus tard, Rio Tinto, et sa région d’adoption. Elle a contribué à consolider une culture régionale de soumission aux capitalistes sans scrupule chez de nombreux élu·e·s des divers paliers de gouvernement[7]. Elle a également vu naitre un héros, un symbole de résistance, celui d’Onésime Tremblay, qui inspirera 100 ans plus tard la fondation d’un Mouvement portant son nom.
Le bail de la rivière Péribonka
Onésime Tremblay et son comité de défense ont proposé de construire des barrages sur la rivière Péribonka, dans cette région moins habitée, plutôt que de rehausser le niveau du lac, ce qui limiterait les dommages au Piékouagami, mais cela au détriment des Innus. L’idée fut reprise par Alcan, qui ne se contenta pas d’avoir rehaussé le lac, considérant ses besoins énergétiques en devenir. Dans les années 1950, la compagnie obtint les droits hydrauliques sous forme de bail sur la rivière Péribonka et y fit construire trois centrales : Chute-du-Diable, Chute-à-la-Savane et Chute-des-Passes. Tout comme les entreprises forestières de l’époque qui produisaient leur électricité, Alcan a échappé à la nationalisation de l’électricité en 1963 en échange d’ententes sur la pérennité de l’approvisionnement et sur l’encadrement de leurs activités.
Le bail de la Péribonka, qui est encadré par une loi, fut renouvelé en 1984 jusqu’en 2033 à certaines conditions. La compagnie s’est engagée à construire ou à moderniser trois usines pour une valeur de trois milliards de dollars (3 G$), afin de réduire ses émissions polluantes et d’augmenter sa production d’un million de tonnes, et ce, avant 2009. Cependant, la compagnie a construit et modernisé deux de ses usines, celle de Laterrière en 1990 et celle d’Alma en 2000, mais elle a tardé à moderniser l’usine d’Arvida, qui en est à sa deuxième phase, la troisième n’étant même pas dans les projets. Alcan avait planifié le remplacement de l’usine d’Arvida en 2009, mais l’achat par Rio Tinto[8] a retardé les projets. La compagnie prévoit le remplacement des cuves précuites par 96 cuves AP60, c’est-à-dire par la moitié des 192 promises, pour le 31 décembre 2025. Les travaux sont en cours, mais la compagnie ne prévoit opérer ces nouvelles cuves que progressivement entre 2026 et 2028. L’autre moitié de l’usine de remplacement est remise aux calendes grecques. Quoi qu’il en soit, au terme de l’installation des 96 cuves AP60 plus performantes, Rio Tinto aura libéré 545 MW d’électricité. Qu’adviendra-t-il de ce surplus ?
Par ces modernisations, Rio Tinto a certes augmenté sa capacité de production[9], mais elle a réduit considérablement le nombre d’emplois, qui sont passés de 12 000 en 1982 à moins de 4 000 aujourd’hui. Comme elle ne pouvait pas respecter la date limite de 2009 pour compléter ses modernisations, elle a obtenu trois prolongations, dont la plus récente se termine le 31 décembre 2025. L’entente de la Péribonka stipule que, si celle-ci n’est pas respectée, elle devient caduque et le gouvernement peut reprendre possession des centrales et des ouvrages connexes à son échéance en 2033. Il est évident qu’au 31 décembre 2025, les engagements de Rio Tinto ne seront pas respectés. La mobilisation citoyenne sera nécessaire pour en tirer les conséquences.
La députée de Chicoutimi et ministre régionale du gouvernement caquiste, Andrée Laforest, s’est faite, jusqu’à sa démission en septembre 2025, la porte-parole efficace de Rio Tinto en affirmant que la compagnie respecte l’entente, ce qui est loin d’être un avis partagé par d’anciens cadres d’Alcan qui ont récemment publié un livre sur le sujet[10].
L’enjeu de l’énergie
Outre les trois centrales sur la Péribonka, Rio Tinto possède trois autres centrales : Isle-Maligne à la sortie du lac Saint-Jean ainsi que Chute-à-Caron et Shipshaw sur la rivière Saguenay. La compagnie a récemment annoncé d’importants travaux de rénovation à la centrale d’Isle-Maligne, au coût de 1,7 G$ d’ici 2032. La production électrique y sera augmentée[11].
La production totale de Rio Tinto dépasse les 3 200 MW, ce qui équivaut à 9 % de la production totale d’Hydro-Québec. Cette électricité, produite au coût variant entre 0,563 et 1 cent le kWh[12], représente pour la compagnie une économie de plusieurs centaines de millions de dollars chaque année.
On se souviendra que, lors du lockout des 850 employés syndiqués de l’usine d’Alma en 2012, Rio Tinto a vendu son électricité excédentaire à Hydro-Québec au prix courant, ce qui lui a procuré des revenus de plus de 100 M$ – certaines sources allant jusqu’à 125, voire, 148 M$. D’aucuns avaient alors suggéré que la compagnie faisait plus d’argent à vendre son électricité qu’à produire de l’aluminium.
Le projet de loi 69 intitulé Loi assurant la gouvernance responsable des ressources énergétiques et modifiant diverses dispositions législatives, adopté sous le bâillon en juin 2025, ouvre la porte aux industriels quant à la production d’énergie privée pour leur usage ou pour vendre à d’autres producteurs[13]. Rio Tinto a justement dans ses cartons un projet de parc éolien visant à produire entre 700 et 1 000 MW dans le secteur de son barrage de Chute-des-Passes[14].
Le gouvernement et Hydro-Québec avaient déjà entrouvert la porte à la production privée d’électricité par le biais des minicentrales et de l’éolien, en alliance avec certaines municipalités, OSBL ou communautés autochtones. Maintenant, ils l’ouvrent toute grande au secteur privé. Ce qui était l’exception, soit la situation des barrages privés du Saguenay-Lac-Saint-Jean, devient applicable partout.
Dans un tel contexte, pour une entreprise, la production d’électricité n’est plus une particularité qui doit être obligatoirement reliée à ses activités industrielles. Cela peut être aussi un commerce payant permis par la loi. À quoi bon soumettre cette activité à des conditions particulières ? L’État, quant à lui, renonce à un levier, celui de la fourniture d’énergie, pour forcer les entreprises à partager, un tant soit peu, les fruits de l’exploitation de nos ressources.
Si certains avaient déjà proposé la nationalisation des barrages privés du Saguenay-Lac-Saint-Jean comme un moyen de compléter enfin la nationalisation de l’hydroélectricité, aujourd’hui, le gouvernement Legault inverse complètement la donne en rendant la production privée d’électricité accessible partout au Québec. L’énergie, et l’électricité en particulier, constitue un bien collectif qui est sur la voie d’une dilapidation accélérée.
Gestion dévastatrice du niveau du réservoir Saint-Jean
Le réservoir Saint-Jean s’agrandit chaque année. Sa circonférence est passée de 210 km à 260 km depuis 1910 et les berges ont reculé de 350 pieds[15]. L’Alcan et, par la suite, Rio Tinto ont régulièrement haussé le niveau du réservoir dans le cadre de leur gestion hydroélectrique, avec pour conséquences les dommages que dénoncent les nombreux riverains et riveraines. Le Programme de stabilisation des berges instauré par le gouvernement en 1986 oblige la compagnie à consulter la population et les autres parties prenantes dans la gestion du niveau du lac. Lors de la négociation du cycle de 2017-2026, l’ensemble des associations de riverains, les municipalités et municipalités régionales de comté (MRC) avaient réclamé une cogestion, ce que le Bureau d’audiences publiques en environnement (BAPE) avait d’ailleurs recommandé en 1985. Philippe Couillard, alors premier ministre et député de Roberval, avait même prétendu appuyer cette demande, mais il l’avait finalement refusée.
Les préparatifs du prochain cycle du Programme de stabilisation des berges, prévu pour 2028-2037, ont commencé. Déjà, l’on réclame la tenue d’un examen public par le BAPE avant qu’une entente intervienne entre Rio Tinto et le gouvernement afin d’éviter de biaiser les travaux du BAPE. La compagnie doit reconnaitre sa responsabilité dans l’érosion des berges de tout le lac, entre autres à Pointe Langevin, en effectuant les réparations nécessaires et en agissant de manière préventive dans l’avenir. La mobilisation citoyenne est cruciale à ce moment-ci. Les diverses associations de riverains, mais également les municipalités et MRC concernées ainsi que le Mouvement Onésime-Tremblay s’activent.
(Je vais mettre à peu près ici une photo de l’érosion)
Un bilan environnemental pitoyable
Rio Tinto est le champion des contrevenants environnementaux au Québec[16], entre autres pour des rejets de contaminants toxiques dans les cours d’eau, dont le Saguenay.
En 2015, Rio Tinto a voulu aménager un site d’entreposage de résidus de bauxite dans le Boisé panoramique, un parc en plein centre de la ville de Saguenay, considéré comme une zone tampon. Il s’agit d’un dépotoir de déchets industriels d’un million de tonnes de résidus de bauxite par an dans un milieu densément peuplé. Le Comité de citoyens pour un Vaudreuil durable a mené la lutte pour exiger un changement de site pendant que le conseil de ville de Saguenay s’est précipité pour dézoner le site, sans étude d’impact, ni même entendre l’avis de son propre Comité consultatif d’urbanisme. À la suite des pressions populaires, la compagnie a instauré une consultation publique. Le commissaire a finalement recommandé de rechercher un site alternatif et de favoriser la participation des parties prenantes. Ce n’est qu’au début de 2025 que Rio Tinto annonce qu’elle recherchera un autre site, mais sans renoncer toutefois au Boisé panoramique[17].
Rio Tinto jouit d’un droit de polluer semblable à celui de la fonderie Horne de Glencore à Rouyn-Noranda. Comme on l’a écrit plus haut, les vieilles cuves précuites d’Arvida devaient être remplacées par des cuves AP60 moins polluantes, au plus tard en 2009, mais cette échéance a été reportée au 31 décembre 2025. La prolongation de 10 ans du délai de fermeture de l’usine d’Arvida a permis à Rio Tinto de réaliser plus de 1 G$ de revenus.
Rio Tinto, un assisté corporatif
Outre les économies que lui permettent les barrages – économies estimées à plus de 700 M$ par an selon Martine Ouellet, ancienne ministre des Ressources naturelles sous le gouvernement Marois et cheffe du parti Climat Québec –, Rio Tinto bénéficie d’un congé d’impôt de 178 M$ par année et d’une exemption de la taxe sur les gaz à effet de serre (crédits carbone) de 300 M$ par année. On peut donc dire que Rio Tinto reçoit année après année une subvention de 1,2 G$ de l’ensemble de la population québécoise[18]. À cela s’ajoutent ponctuellement de multiples prêts, subventions et privilèges accordés au fil du temps : prêt sans intérêt de 400 millions sur 30 ans accordé en 2006, bloc d’énergie réservé à prix avantageux, subventions de 140 M$ et 80 M$ pour recherche et développement et l’implantation de la technologie Elysis[19], un procédé destiné à éliminer les GES – ainsi que de nombreux emplois –, une technologie dont on sait pourtant peu de chose. De plus, si ce procédé s’avère efficace, rien ne nous assure qu’il sera implanté au Québec.
Selon Francis Vailles de La Presse, Rio Tinto n’a pratiquement pas payé d’impôt au gouvernement du Québec ces dernières années pour son secteur aluminium. Entre 2020 et 2023, elle a payé en moyenne 12 M$ d’impôt pour 3 G$ de profits[20].
Selon l’Association des retraité·e·s syndiqué·e·s Rio Tinto Alcan, la compagnie aurait retiré près de 3 milliards de dollars de leur caisse de retraite, en prenant en compte les bénéfices accumulés. Cela inclut les congés de paiement de cotisation (200 M$) hérités d’Alcan, les allégements fiscaux (538 M$) accordés grâce à la loi 57, ainsi que les prêts sans intérêt (266,5 M$) prélevés dans la caisse. Tout cela a pour conséquence de couper l’indexation de la rente des retraité·e·s. Pour l’Association, les retraité·e·s syndiqués financent à eux seuls la modernisation de l’usine d’Arvida[21]. Les employés-cadres ont subi le même traitement par Rio Tinto, dont un prêt sans intérêt à même leur caisse, d’une valeur de 110 M$. En prime, cette modernisation financée par les syndiqués et cadres retraités se soldera par l’abolition de 300 à 400 postes.
La délocalisation des activités de commercialisation nord-américaines de Rio Tinto de Montréal à Chicago et Singapour lui permet de faire des achats pour ses usines du Québec depuis Singapour et ainsi d’avoir des charges fiscales moins importantes qu’au Canada. Rio Tinto est, comme le disent les auteurs Jacques Dubuc et Myriam Potvin, « l’exemple parfait d’engagements non respectés »[22] [23].
Le Mouvement Onésime-Tremblay : un pouvoir citoyen pour contrer la culture de soumission
Si l’on tient compte de l’ensemble des avantages retirés par Rio Tinto de l’exploitation de nos ressources, de ses profits, des congés d’impôt, des subventions et autres bénéfices, il apparait évident que le Saguenay-Lac-Saint-Jean et le Québec ne reçoivent pas, de l’avis de nombreux acteurs sociaux, une contrepartie équitable, que ce soit en matière d’emplois, d’impôts ou de redevances, ou encore en matière de contrats locaux ou de retombées indirectes. L’État du Québec doit cesser de permettre la dilapidation des ressources collectives, il doit reprendre la main et se faire le gardien du bien commun.
À la suite d’un colloque sur les 100 ans d’occupation d’Alcan et Rio Tinto, organisé par Climat Québec et l’Association des retraité·e·s syndiqué·e·s de Rio Tinto Alcan, le 22 octobre 2024 à Jonquière[24], il y eut la formation d’un comité de suivi. Celui-ci a rapidement constaté la nécessité d’avoir un mouvement citoyen pour défendre l’intérêt général et le bien commun devant la domination de Rio Tinto et l’accointance de la plupart des élu·e·s locaux, régionaux et nationaux.
En juin 2018, un buste à la mémoire d’Onésime Tremblay a été érigé dans un parc de Métabetchouan-Lac-à-la-Croix[25]. Le Mouvement Onésime-Tremblay a pu porter son nom avec l’assentiment des descendants et descendantes de celui qui a défendu sans relâche les centaines d’agriculteurs sinistrés par l’inondation causée par le rehaussement du lac Saint-Jean, et ce, illégalement et sans préavis.
Les objectifs du Mouvement Onésime-Tremblay sont de :
- favoriser l’expression et la diffusion d’un point de vue citoyen axé sur le bien commun face à l’impact des actions passées, présentes et futures d’Alcan et Rio Tinto ;
- contribuer à la reprise en main de nos ressources électriques dans l’intérêt de la collectivité, les ressources électriques désignant autant l’hydroélectricité que l’éolien.
Les moyens envisagés sont de privilégier des actions publiques sur des lieux significatifs de façon à s’assurer du maximum de visibilité, ainsi que de recourir à l’éducation populaire et à la mobilisation.
Le mouvement est actuellement en phase d’implantation. Une campagne de promotion et d’adhésions est en cours. On prévoit des actions dans le cadre de la préparation du prochain cycle du Programme de stabilisation des berges 2028-2037, ainsi que du centenaire de la tragédie du lac Saint-Jean en juin 2026. L’échéance du 31 décembre 2025 pour la mise en œuvre des conditions du bail de la Péribonka est également à l’ordre du jour.
Le mot de la fin revient à Onésime Tremblay : « Nous lutterons tant qu’il nous restera un souffle de vie. Nous perdrons peut-être des biens qui nous ont coûté une vie de labeur. Mais nous laisserons après nous quelque chose qui vaut mieux. Un honneur intact et l’exemple du devoir accompli ».
Par Pierre Dostie, militant politique et membre du Mouvement Onésime-Tremblay
- Je remercie Germain Dallaire, Mishell Potvin, Denis Trottier et Éric Scullion pour leurs commentaires. ↑
- En 1926, on parlait de la Chambre législative et non de l’Assemblée nationale dont le nom a été adopté en 1968. ↑
- Nom donné au lac Saint-Jean par les Pekuakamiulnuatsh et qui signifie « lac peu profond ou lac plat ». ↑
- Nom Innu qui signifie « lieu de débarquement » selon l’ONF et « là où l’eau monte un peu » selon la Commission de toponymie. ↑
- Germain Dallaire. À l’ombre d’Alcan. Histoire, Chicoutimi, Les classiques des sciences sociales, 2023. ↑
- Onésime Tremblay, dans Le combat d’Onésime Tremblay, film documentaire réalisé par Jean-Thomas Bédard, ONF, 1985. ↑
- Soulignons ici un autre cas de relèvement des eaux au Saguenay, celui du lac Kénogami, en 1924, deux ans avant celui du lac Saint-Jean, à la demande des compagnies de pulpe pour faire du lac un immense réservoir pour la production d’électricité et le flottage de bois. Le village de Saint-Cyriac, vieux d’une soixantaine d’années, a été englouti, de même que les terres cultivées aux alentours. Les villageois ont été expropriés et forcés de déménager avec un dédommagement loin d’être à la hauteur des pertes et préjudices. ↑
- Rio Tinto a acheté Alcan en 2007 et elle est liée par une entente de continuité, c’est-à-dire qu’elle s’est engagée à respecter les engagements qu’Alcan avait pris envers le gouvernement québécois avant elle. ↑
- Cependant, la compagnie s’était engagée à augmenter sa capacité de production d’aluminium de 450 000 tonnes et à créer 740 emplois à Arvida, ce qui est loin d’être le cas. ↑
- Jacques Dubuc et Myriam Potvin, L’exploitation de notre eau par Rio Tinto, Quel avenir pour le Québec ? Montréal, Somme toute, 2025. ↑
- François Normand, « PL69 : Rio Tinto Alcan a failli perdre le droit de vendre son électricité à des entreprises », Les Affaires, 5 juin 2025. ↑
- Le tarif résidentiel se situe entre 4,774 et 8,699 cents le kWh selon la consommation l’hiver, et entre 6,905 et 10,652 cents le kWh l’été. ↑
- Assemblée nationale du Québec. Loi assurant la gouvernance responsable des ressources énergétiques et modifiant diverses dispositions législatives. ↑
- Thomas Gerbet, « Rio Tinto prépare un gros projet d’éoliennes sans Hydro-Québec », Radio-Canada, 16 janvier 2024. ↑
- Voir le film Le combat d’Onésime Tremblay, op. cit. ↑
- Ulysse Bergeron, « Rio Tinto, géant des mines… et des infractions », dossier de La Presse, 15 février 2025. ↑
- Myriam Gauthier, « Rio Tinto abandonne l’idée d’un site de résidus de bauxite dans le boisé panoramique », Radio-Canada, 23 janvier 2025. ↑
- Martine Ouellet, « Rio Tinto Alcan et la CAQ : ça suffit de rire de nous ! », Journal de Montréal, 3 juin 2023. ↑
- Ibid. ↑
- Francis Vailles, « Le Québec, paradis fiscal des alumineries », La Presse, 12 décembre 2022. ↑
- Association des retraité·e·s syndiqué·e·s Rio Tinto Alcan, Lettre au premier ministre M. François Legault, au sujet de l’annonce de la construction de 96 cuves AP-60 à Arvida, 3 août 2023 et Pascal Girard, « Les syndiqués retraités de Rio Tinto demandent l’intervention de François Legault », Radio-Canada, 8 août 2023. ↑
- Dubuc et Potvin, 2025, op. cit. ↑
- Solveig Beaupuy, « Rio Tinto, l’exemple parfait d’engagements non respectés ». Le Quotidien, 25 mai 2025. ↑
- Climat Québec, Colloque : bilan 100 ans RTA, 5 vidéos. ↑
- Jonathan Hudon, « La mémoire d’un bâtisseur honoré », Le Quotidien, 25 juin 2018. ↑

1825-2025 : de la rançon-dette à la colonialité en Haïti

Cet article est tiré d’une présentation donnée dans le cadre du colloque La Grande Transition en mai 2025 à l’Université du Québec à Montréal.
Plusieurs événements majeurs ont marqué le XIXe siècle haïtien : la victoire de l’armée indigène sur l’armée napoléonienne le 18 novembre 1803 qui aboutit à la proclamation de l’indépendance d’Haïti le 1er janvier 1804, l’assassinat du premier chef d’État d’Haïti le 17 octobre 1806 par l’oligarchie naissante et l’occupation étatsunienne d’Haïti de 1915, scellant la fin du siècle, déjà fragilisé par les balbutiements de la colonialité amorcés avec la rançon imposée par la France en 1825 qui ouvre l’ère de la domination impérialiste étatsunienne en Haïti. La Révolution haïtienne représente le questionnement le plus radical à la modernité coloniale capitaliste, esclavagiste et raciste, et constitue une révolution décoloniale[31]. Elle porte en elle des idéaux qui redéfinissent et posent les fondements philosophiques et ontologiques d’une véritable liberté et égalité entre les êtres humains. Elle donne naissance à une nation indépendante et souveraine.
En effet, elle était considérée comme une menace pour la stabilité de l’ordre mondial colonial raciste. Elle a été rendue invisible, occultée, banalisée, voire impensable dans l’historiographie dominante, jusqu’à un passé récent[2]. Pendant deux décennies, la France a mené une politique de mise en quarantaine et d’isolement d’Haïti au sein du concert des nations[3]. L’ancienne métropole, vaincue par d’anciens captifs lors de la bataille de Vertières, n’a jamais accepté cette défaite ni l’indépendance d’Haïti. D’où, l’imposition du roi de France Charles X, le 17 avril 1825, d’une rançon[4] ou une rançon néocoloniale[5] à la nouvelle nation haïtienne indépendante et souveraine depuis 1804.
L’année 2025 marque deux cents ans de cette gifle à la Révolution haïtienne. L’administration du président haïtien de l’époque Jean Pierre Boyer a accepté de payer cette rançon. Boyer a apposé sa signature le 8 juillet et le Sénat haïtien l’a ratifiée le 11 tel qu’exigé par la France. Le lendemain, Jean Pierre Boyer a annoncé l’information[6]. Ainsi, « Juillet 1825 met un terme à dix ans de rencontres officieuses et de pourparlers au sujet de la souveraineté d’Haïti[7] ». Certains auteurs et autrices évoquent une double dette, puisqu’Haïti a dû emprunter auprès des banques françaises pour payer une telle somme[8]. D’autres désignent cette exigence comme une rançon[9] ou une rançon néocoloniale[10]. Brière[11] y voit, de son côté, une tentative d’instaurer un régime néocolonial alors que Doubout (1973), Hector et Casimir (2004) et Hector (1998)[12] analysent cette mesure comme un renforcement du caractère semi-colonial du pays. Ernatus (2009)[13]emploie le terme « indemnité coloniale », alors que Zambrana (2021)[14]privilégie celui de « dette coloniale ».
Dans cet article, je m’appuie principalement sur la philosophe portoricaine Rocío Zambrana pour soutenir la thèse que la rançon-dette est plutôt un nouveau mécanisme financier visant à établir la colonialité, et qu’à ce titre, elle constitue une arme contre-révolutionnaire et un obstacle au déploiement et à l’application des idéaux de la Révolution haïtienne. En conséquence, la rançon-dette est une forme de colonialité qui prend corps dans la domination coloniale de la France et l’exploitation de la classe paysanne par l’État et l’oligarchie pour payer. J’adopte plutôt la terminologie de rançon-dette, puisque l’imposition de la France à payer la somme réclamée résulte d’une opération de capture. Ainsi, cette rançon va amener le pays à intégrer une spirale d’endettement en empruntant dans les banques françaises.
La Révolution haïtienne : une menace à contenir
Saint-Domingue, ancienne colonie française, la plus prospère appelée « La perle des Antilles », a connu des années de bouleversement jusqu’à son effondrement par la Révolution de 1791-1803. Le 18 novembre 1803 marque la dernière bataille, ce fut la Victoire de l’armée indigène contre l’armée française napoléonienne. Cette Révolution a donné naissance à une nation haïtienne souveraine et indépendante. Elle a non seulement permis de sortir de l’esclavage, elle a aussi créé le fondement ontologique même de l’humain : tout moun se moun (toute personne est un humain) libète osnon lanmò (liberté ou la mort). Il s’agissait d’une révolution anticoloniale, anti-esclavagiste et antiraciste[15]. Si la Révolution haïtienne, réalisée par des captifs[16] remet en question le fondement philosophique et ontologique de la modernité coloniale capitaliste raciste, elle a été pourtant pendant longtemps inivisibilisée et le pays a été isolé dans le concert des nations.
Par ailleurs, pour Quijano et al. (2014)[17], la Révolution haïtienne, étant la première grande révolution moderne, désigne le premier moment de la désintégration de la colonialité du pouvoir et articule indépendance nationale, décolonisation du pouvoir social et révolution sociale. De son côté, Mignolo (2015)[18] avance qu’il s’agit d’une révolution décoloniale. Jean Casimir explique que : « La nation haïtienne est une réponse aux agissements de l’État moderne, capitaliste et raciste[19] ». Elle a bousculé toutes les idées racistes et a ouvert une nouvelle ère de l’histoire pour l’ensemble des peuples non occidentaux subissant la domination coloniale esclavagiste[20]. Susan Buck-Morss[21] a minutieusement montré comment Hegel a complètement ignoré que sa théorisation de la dialectique du maitre et de l’esclave se nourrit de la dynamique révolutionnaire de Saint-Domingue.
C’est à la fois la radicalité de la révolution qui fait peur même à certains qui prétendent défendre la liberté et l’égalité entre les humains, mais aussi, et surtout il s’agit d’une révolution menée par des personnes que la pensée moderne coloniale peine à accepter comme des Humains à part entière. Cette volonté de passer sous silence et dans l’ignorance cette révolution découle de la volonté des puissances colonialistes esclavagistes capitalistes impérialistes de maintenir le monde colonial. La Révolution haïtienne est ainsi devenue une menace, car elle montre aux autres captifs des autres colonies la possibilité de se frayer une voie vers la liberté en détruisant par les luttes révolutionnaires le système colonial. Cette mise en quarantaine d’Haïti n’est pas sans relation avec cette ordonnance imposée par la France. S’il devient de plus en plus difficile d’isoler et de contenir Haïti et sa révolution, les puissances coloniales impériales mettent tout en place pour faire du pays un mauvais exemple. D’où l’idée de cette rançon, l’invisibilisation ne suffit plus.
Rançon-dette : mécanisme financier de la colonialité
En intégrant Haïti au système financier international dès le XIXe siècle, la rançon de 1825 a plongé le pays dans une spirale d’endettement durable. Ce mécanisme, loin d’être une simple transaction, témoigne du bras financier de la colonialité, par lequel la domination post-esclavagiste s’est perpétuée sous des formes économiques. Il s’agit d’un mécanisme stratégique de la France afin de restaurer sa domination coloniale sur Haïti comme nation indépendante et souveraine depuis 1804. La rançon-dette devient une forme de colonialité et un levier contre-révolutionnaire afin d’empêcher la concrétisation des idéaux portés par la Révolution haïtienne, tant sur le plan matériel que culturel. Donc, le projet politico-philosophique que charrie le slogan du créole haïtien tout moun se moun, pa gen moun pase moun [personne n’est supérieur à autrui], qui renverse toutes les idées racistes classifiant les populations, les groupes en supérieurs, inférieurs… ne doit pas devenir une réalité pleine et entière pour les Haïtiens et Haïtiennes.
Dans ces conditions, la rançon-dette apparait avant tout comme un instrument de neutralisation du symbolisme de 1804, visant à maintenir Haïti dans une position de subordination au sein de l’ordre mondial colonial. Elle inscrit le pays dans une nouvelle phase historique marquée par la colonialité, où les formes de domination ne relèvent plus du colonialisme classique, mais de mécanismes économiques, politiques et épistémiques. On observe ainsi un glissement du colonialisme vers la colonialité, témoignant de la transformation des logiques impériales dans le contexte post-esclavagiste.
La colonialité diffère en effet du colonialisme. Ce dernier requiert l’intervention directe de la métropole à travers une administration coloniale établie dans la colonie et une forme de contrôle juridico-politique. En revanche, la colonialité est plutôt une forme de rapport colonial sans la présence des administrations coloniales dans des contextes de pays indépendants sur le plan juridico-politique[22]. La France, à travers le mécanisme de la rançon et de la dette, voulait instituer ce régime de colonialité en Haïti. Ainsi, l’imposition par la France et ses alliés à Haïti en réponse à la Révolution est le premier cas de dette utilisée comme un appareil pour perpétuer la condition coloniale. Bien que l’analyse de Zambrana ne porte pas directement sur le XIXe siècle haïtien, elle éclaire de manière pertinente les enjeux de la dette dans le processus de colonialité. Elle affirme que la dette fonctionne comme un appareil de capture, de prédation et d’extraction dans le capitalisme financiarisé néolibéral, et qu’elle nécessite l’intervention des États pour se concrétiser, comme ce fut le cas d’Haïti.
Zambrana ajoute que son fonctionnement implique l’expulsion, la dépossession et la précarisation qui renforcent, intensifient et réaffirment les hiérarchies raciales, de genre et de classe[23]. Donc, la dette doit être comprise comme une forme de colonialité qui correspond à un mode de relation sociale, économique et politique. Partant de cette posture, mes propos se distinguent, d’une part, d’un certain discours qui met seulement l’accent sur la pression militaire de la France comme justificatif d’acceptation de la rançon ; d’autre part, de l’idée que la population haïtienne a célébré une telle ordonnance. Jean Marie Théodat[24] affirme dans cette optique : « Cette ordonnance aujourd’hui présentée comme une somme indue par les militants, fut en son temps célébrée par les autorités et la population ». Je me demande sur quelles données empiriques et historiques se fonde une telle assertion. Et comment peut-on expliquer que les démarches ont été menées dans la clandestinité jusqu’en 1825 ? En réalité, la question est de quel lieu parle-t-on de cette ordonnance ?
« Shariana Ferrer-Núñez souligne à juste titre que la manière dont nous sommes orientés, où nous nous situons, lorsque nous parlons de la dette, est cruciale. Le cas d’Haïti est exemplaire du fonctionnement de la dette en tant qu’appareil de capture et de prédation, mais aussi en tant que forme de colonialité[25]. » Car si la rançon-dette a des coordonnées spatio-temporelles[26], de quel lieu se sont tenus les discours la concernant ? Est-ce du bateau ou de la plage ? Si c’est depuis le bateau, c’est-à-dire depuis une perspective coloniale, on parle de dette et on peut entrevoir une célébration de la population par une extrapolation du contentement des Anciens libres, comme on peut l’expliquer par la faiblesse de l’État, voire la faiblesse des deux États. Si c’est depuis la plage, on parle de rançon ou du couple rançon-dette dans le sens que cette opération a introduit le pays dans la spirale de dette et d’endettement comme mécanisme financier de la colonialité. En ce sens, comme rapport social, cette logique coloniale de rançon-dette structure un rapport de pouvoir. Il est en effet indispensable de regarder le type de rapport que l’oligarchie et l’État a historiquement développé avec la classe paysanne. Il s’agit d’un rapport d’exclusion sociale, d’exploitation, de prédation, de ségrégation sociospatiale (moun andeyò/moun lavil). Le monde rural est construit comme pays en dehors[27], il est une zone de non-être[28] longtemps abandonné quand il s’agit de services publics, mais une vache à lait quand c’est pour l’exploiter de toutes sortes. Un tel rapport nourrit une contradiction historique entre l’État et le peuple souverain, Jean Casimir l’identifie en tant qu’interminable dialogue de sourds. Ces rapports teintés de mépris orientent le choix du régime de Boyer d’accepter cette rançon dans la plus grande opacité.
Le choix du président Jean-Pierre Boyer d’accepter l’ordonnance est une position politique qui répond aux intérêts de sa classe. Laquelle classe s’est toujours perçue comme Français ou descendant de colons français et souhaite avoir une reconnaissance en développant des rapports harmonieux avec leurs ancêtres colons blancs. D’ailleurs, ils ont toujours réclamé les héritages des anciens colons français. On se rappelle les propos de Jean Jacques Dessalines, assassiné le 17 octobre 1806, affirmant que si les pauvres noirs, dont les pères sont en Afrique, n’auront bénéficié de rien lorsque cette classe a voulu tout accaparer, le pouvoir politique et les richesses principalement la terre à l’époque. Cependant, cette classe, semble-t-il, se heurte à un obstacle : la blanchité. Samuel Morancy[29] décrit un défi externe difficilement surmontable : « celui de faire accepter aux puissances coloniales et ex-coloniales les métis et les noirs comme interlocuteurs politiques sur la scène internationale avec une représentation européenne de l’humanité ou de la colonialité de l’être ». Il souligne une particularité d’Haïti dans les Amériques : une colonialité sans blanchité[30]. Donc, il était pour cette oligarchie une nécessité d’avoir la reconnaissance de l’ancienne métropole.
Je n’ignore pas pourtant la pression ou les menaces de la France. D’ailleurs, c’est « sous la menace d’un bombardement de la capitale de Port-au-Prince, l’ordonnance reçoit l’aval du gouvernement haïtien cinq jours seulement après l’arrivée de Mackau, le 8 juillet 1825[31] ». Cependant, ces pressions ou menaces ne déterminent pas forcément la décision de Boyer. D’ailleurs le roi Henri Christophe a décidé autrement malgré ces menaces. En revanche, Alexandre Pétion a proposé en 1814 une indemnité et il a même demandé à la France d’acheter Saint-Domingue déclarant que « le gouvernement français ferait bien mieux, pour lui et pour les anciens propriétaires, de nous vendre Saint-Domingue comme il a vendu la Louisiane aux États-Unis[32] ».
Jean Casimir a soutenu une telle thèse dans un webinaire organisé par International Center for Multigenerational Legacies of Traumas sous le thème Unvelling the legacy : Scholarly reflections on Haiti’s « double debt » of 1825, le 15 septembre 2025. Il argumente que :
Donc, lorsque Boyer est allé livrer le peuple haïtien, les mains et les pieds liés, sans donner la moindre explication à qui que ce soit, il savait parfaitement ce qu’il faisait. Boyer défendait sa présidence, il protégeait la position de ses compagnons qui avaient débarqué avec Leclerc pour rétablir l’ordre. Il défendait aussi ceux qui avaient conspiré pour tuer Moïse, Charles et Sanite Bélair, tous les chefs marron, ainsi que Dessalines, comme « dessert sanglant » au Pont-Rouge. Ce sont ces mêmes personnes qui avaient proposé d’acheter Saint-Domingue, de la même manière que les États-Unis avaient acheté la Louisiane. Mais Boyer est allé encore plus loin que tous les anciens libres réunis : il a livré le pays aux Blancs, car après lui, l’État n’avait plus la force de négocier ne serait-ce qu’une petite parcelle d’autonomie.
Les propos des émissaires français étaient clairs à propos de la volonté de la France de rétablir le système colonial raciste. Les propos du ministre des Colonies Malouet en 1814, cités par François Blancpain, en témoignent :
Les intentions paternelles de Sa Majesté étant de rétablir l’ordre et la paix dans toutes les parties de ses États par les moyens les plus doux. Elle a résolu de ne déployer sa puissance pour faire rentrer les insurgés de Saint-Domingue dans le devoir qu’après avoir utilisé toutes les ressources qui lui inspirent sa clémence. C’est plein de cette pensée que le Roi a porté ses regards sur la colonie de Saint-Domingue. […] Si Pétion tombe d’accord de placer l’homme de couleur, jusqu’au mulâtre inclusivement, un au-dessous du blanc, il devient beaucoup plus facile de restreindre les privilèges de la caste au-dessous de celle-là (composée de nuances entre le mulâtre et le nègre) et ceux des nègres libres, si l’on établit ces trois castes intermédiaires entre le blanc, et le nègre esclave. […] Quant à la classe la plus considérable en nombre, celle des noirs attachés à la culture et aux manufactures de sucre, d’indigo, etc., il est essentiel qu’elle demeure ou qu’elle rentre dans la situation où elle était avant 1789, sauf à faire des règlements sur la discipline à observer, telle que cette discipline soit suffisante au bon ordre et à une somme de travail raisonnable, mais n’ait rien de trop sévère. Il faudra, de concert avec Pétion, aviser au moyen de faire rentrer dans les habitations et dans la subordination le plus grand nombre de noirs possible, afin de diminuer celui des noirs libres. Ceux que l’on ne voudrait pas dans cette dernière classe et qui pourraient porter un esprit d’insurrection trop dangereux devront être transportés dans l’ile de Ratau ou ailleurs[33]…
La logique coloniale raciste et la volonté d’instaurer la domination coloniale de la France sont évidentes dans ces propos. Il n’y a donc pas l’ombre d’un doute que le projet demeure le rétablissement de la domination coloniale. La rançon-dette était donc la stratégie. L’ordonnance ne mentionne jamais Haïti, elle fait toujours référence à Saint-Domingue, le nom de l’ancienne colonie française. Alors que la nouvelle nation indépendante et souveraine a doté le pays du nom d’avant la colonisation, Haïti. L’ordonnance parle de la partie française de Saint-Domingue. Vu le contexte, un retour au colonialisme classique tel qu’il a été n’a pas été possible. D’où la dette est une forme de colonialité : « Cette double “dette d’indépendance” apparaît clairement comme la stratégie mise en place par l’ancienne métropole pour conserver une hégémonie officieuse sur une colonie rebelle devenue État souverain. Faute d’une domination politique directe, Haïti est désormais placée de manière durable sous l’emprise économique de la France[34] ». Mais, c’est à quel prix ?
La rançon-dette : une entrave pour l’avenir
Cette rançon qui a initié le pays dans la spirale de dette a de grandes conséquences à tous les niveaux sur le pays. Elle a instauré la colonialité en restaurant l’autorité coloniale de la France, et en même temps a entériné la « dépendance historico-structurelle[35] » du pays. L’article 1 exige la réduction de moitié des droits de douane pour la France, le second précise le montant de la rançon qui est de 150 millions de francs. Le dernier entérine ladite reconnaissance de l’indépendance acquise sous le feu et le sang des combattants. L’État en Haïti doit emprunter aux banquiers français pour octroyer ce paiement. Et ce sont des conditions desquelles devrait découler une « concession de l’indépendance » de la part de la France.
Pour exécuter cette ordonnance, Boyer a pris une série de mesures. Il fait voter une loi, le 20 février 1825, déclarant la rançon « dette nationale ». La loi d’application fiscale du 1er mai 1826 impose un impôt de 30 millions de gourdes sur 10 ans fixant le montant que les contribuables des communes et des arrondissements doivent verser. Les 150 millions de francs équivalent à trois ans de production haïtienne en 1825, soit 300 % du PIB, six fois les recettes officielles du gouvernement selon Beaubrun Ardouin[36], dix années de recette fiscale du pays, six fois les revenus officiels du gouvernement. Alors, la dette devient l’une des armes puissantes de domination des puissances impérialistes[37]. Et « La double dette contribuera à entrainer Haïti dans une spirale d’endettement qui l’affaiblira pendant plus de 100 ans, siphonnant une grande partie de ses revenus et entravant sa capacité à construire les institutions et les infrastructures indispensables à toute nation indépendante[38]. »
L’administration de Boyer a produit un code rural, celle du 20 mai 1826, qui considère les paysans comme des personnes attachées à la terre et qui travaillent pour les comptes de l’État. Toutes les personnes non propriétaires du monde rural qui ne travaillent pas sont susceptibles d’être punies pour vagabondage. La paysannerie est la classe exploitée pour payer les anciens colons : « […] c’est le paysan haïtien, producteur de café, qui, par le biais des taxes douanières, paie la “double dette”, c’est-à-dire la dette extérieure et ses annexes[39] ». Ainsi, « Le café du paysan était au gouvernement ce que la laine du mouton est au berger[40] ». Cependant, cette tentative de retour au système de travail forcé se heurta à une forte résistance paysanne aboutissant à une opposition populaire au régime de Boyer[41]. C’est tout ce processus qui construit la dépendance historico-structurelle[42] du pays. Donc, une dépendance financière envers la France perdura jusqu’à son remplacement par celle vis-à-vis des États-Unis en 1915[43].
Le journal étatsunien, The New York Times, a mené une enquête sur la rançon. En espérant qu’il en produira une également sur les pillages des États-Unis en Haïti en commençant par le vol de la réserve d’or d’Haïti en décembre 1914, son enquête relate que :
D’après nos calculs, Haïti a déboursé environ 560 millions de dollars en valeur actualisée. Mais cette somme est loin de correspondre au déficit économique réel subi par le pays. Si elle était restée dans l’économie haïtienne et avait pu y fructifier ces deux derniers siècles au rythme actuel de croissance du pays — au lieu d’être expédiée en France sans biens ni services en retour —, elle aurait à terme rapporté à Haïti 21 milliards de dollars. Et cela même en tenant compte de la corruption et du gaspillage notoires dans le pays. À titre de comparaison, c’est bien davantage que le produit intérieur brut d’Haïti en 2020.
Mais d’autres assurent que, sans le fardeau de la double dette, Haïti aurait pu se développer au même rythme que ses voisins d’Amérique latine. « Il n’y a aucune raison pour qu’un Haïti libéré du fardeau français n’aurait pas pu le faire », soutient l’historien économique Victor Bulmer-Thomas, spécialiste des économies de la région. André A. Hoffman, expert du développement de l’Amérique latine, estime le scénario « très raisonnable », lui aussi. Si l’on prend cette hypothèse, le manque à gagner pour Haïti est stupéfiant, de l’ordre de 115 milliards de dollars, soit huit fois la taille de son économie en 2020[44].
Ces données ont montré comment le paiement de cette rançon est dévastateur pour la nation. La dette-rançon est en effet un outil contre-révolutionnaire et désigne un obstacle à la pleine réalisation des idéaux de la Révolution haïtienne. La rançon-dette a aussi des conséquences écologiques lourdes. Le tableau suivant trouvé dans l’ouvrage d’Alex Bellande et reproduit ici démontre le désastre écologique :
Exportation de bois par port (moyenne annuelle entre 1818 et 1821)
| Cayes | Jacmel | Port-au-Prince | Cap-Haïtien | |
| Campeche | 1.470.000 | 315 000 | 1.900.000 | 174 000 |
| Acajou (pieds) | 11 700 | 90 000 | 13 600 | 1 700 |
| Gaïac et fustic (lbs.) | 144 300 | 17 000 | 27 000 | … |
Source : Mackenzie, 1830
Selon Bellande[45], cette politique de coupe et d’exportation de bois s’inscrit dans la volonté de Boyer de trouver rapidement des revenus pour assurer le paiement de la rançon. La rançon entraine une dette écologique qui peut regrouper quatre différentes dettes non développées ici : dette historique, dette environnementale, dette climatique et dette sociale[46].
Somme toute, la rançon-dette imposée par la France à Haïti en 1825 constitue un mécanisme financier visant à établir la colonialité en Haïti. Elle est une stratégie visant à maintenir les relations coloniales dans le pays nouvellement indépendant. Cette colonialité s’est manifestée, d’une part, à travers les relations de classe, les relations entre l’État et les anciens captifs devenus paysans et, d’autre part, à travers les nouvelles relations entre les puissances impérialistes, en particulier la France et Haïti dans ce contexte. En effet, la rançon-dette en tant que mécanisme d’établissement de la colonialité en Haïti devient une stratégie contre-révolutionnaire visant à interrompre la réalisation des idéaux de la Révolution haïtienne. La dette devient une des expressions financières de la colonialité et elle entrainera le pays dans une spirale d’endettement pendant un siècle qui empêche son développement socioéconomique. Je conclus que la dette est un nouveau mécanisme financier d’instauration de la colonialité et, en tant que telle, elle est une arme contre-révolutionnaire et un obstacle au déploiement et à l’application des idéaux de la Révolution haïtienne.
Le débat sur la rançon-dette ne peut se faire sans poser les questions de la restitution, de la réparation et du dédommagement. Le tout doit être encadré de discours et de pratiques de luttes ancrées dans les idéaux de la Révolution haïtienne dans la perspective de récupérer la souveraineté du pays. Aucun chef d’État n’a osé soulever cette question sauf Jean-Bertrand Aristide en 2003, mais il a été éjecté du pouvoir[47] par un coup d’État orchestré par des puissances impérialistes, en complicité comme toujours avec des traitres au niveau national. Il y a eu même intervention directe de la France dans ce coup d’État à cause de la demande de restitution[48]. Ce qui est confirmé, selon l’enquête du The New York Times, par M. Burkard qui répond : « C’est probablement ça aussi un peu ». La demande, ajoute-t-il, « aurait été un précédent pour 36 autres réclamations[49] ». La lutte pour la restitution/réparation est donc avant tout la lutte des peuples.
Par Walner Osna, doctorant en sociologie, chargé de cours à l’Université d’Ottawa et co-fondateur du Centre de recherche interdisciplinaire et de valorisation des savoirs sur Haïti (CRIVASH) de l’Université d’Ottawa.
- Jean Casimir, Une lecture décoloniale de l’histoire des Haïtiens. Du Traité de Ryswick à l’occupation américaine (1897-1915), Éd. Jean Casimir, 2018 ; Jean Casimir, La nation haïtienne et l’État, Paris, Les Éditions du CIDIHCA, 2018 ; Walter Mignolo, La désobéissance épistémique. Rhétorique de la modernité, logique de la colonialité et grammaire de la décolonialité, Bristol, P.I.E. Peter Lang, 2015 ; Aníbal Quijano, Danilo Assis Clímaco, Cuestiones y horizontes : de la dependencia histórico-estructural a la colonialidad/descolonialidad del poder : antología esencial, Colección Antologías, Buenos Aires, CLACSO, 2014. ↑
- Jean-Claude Le Glaunec, L’armée indigène. La défaite de Napoléon en Haïti, Montréal, Lux éditeur, 2020 ; Claudy Delné, La Révolution haïtienne dans l’imaginaire occidental : occultation, banalisation, trivialisation, Port-au-Prince, Éditions de l’Université d’État d’Haïti, 2017 ; Michel-Rolph Trouillot, Silencing the Past. Power and the Production of History, Boston, Beacon Press, 2015 ; Raúl Esteban DÍAZ ESPINOZA, « La invisibilización de la Revolución de Haití y sus posibles resistencias decoloniales desde la negritud », Relaciones Internacionales, no 25, 2014, p. 25 ; Gurminder K. Bhambra, « Global social thought via the haitian Revolution », dans Boaventura de Sousa Santos et Maria Meneses (dir.), Knowledges Born in the Struggle. Constructiong Th Epistemologies of the Global South, New York, Routledge, 2020. ↑
- Gusti-Klara Gaillard-Pourchet, « Haïti-France. Permanences, évolutions et incidences d’une pratique de relations inégales au XIXe siècle », La Révolution française, no 16, 2019 ; Gusti-Klara Gaillard-Pourchet, « “Dette de l’indépendance” d’Haïti (1825). Cannonière et huis clos pour une rançon néocoloniale », dans Haïti-France. La chaîne de la dette. Le rapport Mackau (1825), Paris, Hémisphères Éditions, 2021. ↑
- Sophie Perchellet, Haïti. Entre colonisation, dette et domination. Deux siècles de luttes pour la liberté !, CADTM, 2010. ↑
- Gaillard-Pourchet, 2021, op. cit. ↑
- Jean-François Brière, Haïti et la France, 1804-1848. Le rêve brisé, Paris, Karthala, 2008. ↑
- Gaillard-Pourchet, 2021, op. cit., p. 73. ↑
- François Blancpain, La condition des paysans haïtiens. Du Code noir aux codes ruraux, Paris, Karthala Editions, 2003 ; François Blancpain, « Note sur les “dettes” de l’esclavage : le cas de l’indemnité payée par Haïti (1825-1883) », Outre-mers, vol. 90, n° 340, 2003. ↑
- Perchellet, 2010, op. cit. ↑
- Gaillard-Pourchet, 2021, op. cit. ↑
- Brière 2008, op. cit. ↑
- Jean Jacques Doubout, Haïti, féodalisme ou capitalisme ? Essai sur l’évolution de la formation sociale d’Haïti depuis l’indépendance, 1973 ; Michel Hector et Jean Casimir, « Le long XIXe siècle haïtien », Revue de la Société Haïtienne d’Histoire et de Géographie, no 216, 2004, p. 37‑56 ; Michel Hector, « Mouvements populaires et sortie de crise (XIXe-XXe siècles) », Pourvoirs dans la Caraïbe, n° 10, 1998. ↑
- Cécile Ernatus, « L’indemnité coloniale de 1849, logique de solidarité ou logique coloniale ? », Bulletin de la Société d’Histoire de la Guadeloupe, no 152, 2009, p. 61‑77. ↑
- Rocio Zambrana, Colonial Debts. The Case of Puerto Rico, Durham, NC, Duke University Press, 2021. ↑
- Laënnec Hurbon, « La révolution haïtienne : une avancée postcoloniale », Rue Descartes n° 58 (4), 2007, p. 56‑66. ↑
- Jean Casimir, Haïti et ses élites. L’interminable dialogue de sourds, Port-au-Prince, Éditions de l’Université d’État d’Haïti, 2009. ↑
- Quijano et al., 2014, op. cit. ↑
- Walter Mignolo, La désobéissance épistémique. Rhétorique de la modernité, logique de la colonialité et grammaire de la décolonialité, Bristol, P.I.E. Peter Lang, 2015. ↑
- Casimir, La nation haïtienne et l’État, 2018, op. cit. ↑
- Hurbon, 2007, op. cit. ↑
- Susan Buck-Morss, Hegel et Haïti, Paris, Lignes, 2006. ↑
- Aníbal Quijano, « Coloniality and Modernity/Rationality », Cultural Studies, vol. 21, n° 2‑3, 2007, p. 168‑78. ↑
- Rocio Zambrana, Colonial Debts. The Case of Puerto Rico, Durham, NC, Duke University Press, 2021. ↑
- Jean-Marie Théodat, « Géopolitique des faibles », dans Marcel Dorigny, Jean-Marie Dulix Théodat, Gusti-Klara Gaillard-Pourchet, Jean-Claude Bruffaerts (dir.), Haïti-France. La chaîne de la dette. Le rapport Mackau (1825), Paris, Hémisphères Éditions, 2021, p. 50. ↑
- Zambrana, 2021, op. cit. ↑
- Ibid. ↑
- Barthélemy, Gérard. 1990. L’univers rural haïtien : le pays en dehors. L’Harmattan. ↑
- Frantz Fanon, Peau noire, masques blancs, Paris, Seuil, 1952. ↑
- Samuel Morancy, « Colonialidade sem branquitude : entre dilema e desafio da integração do Haiti no Sistema-Mundo neocolonial », Le Monde diplomatique, 3 juin 2025. ↑
- Ibid. ↑
- Beauvois, Frédérique, « L’indemnité de Saint-Domingue : “Dette d’indépendance” ou “rançon de l’esclavage”? », French Colonial History, vol. 10, 2009, p. 115. ↑
- Extrait du journal de Dauxion, dans Beauvois, 2009, op. cit., p. 112. ↑
- François Blancpain, Un siècle de relations financières entre Haïti et la France (1825-1922), Paris, L’Harmattan, 2001, p. 45-47. ↑
- Beauvois, 2009, op. cit., p. 119. ↑
- Quijano, 2014, op. cit. ↑
- Catherine Porter, Constant Méheut, Matt Apuzzo, et Selam Gebrekidan, « À la racine des malheurs d’Haïti : des réparations aux esclavagistes », The New York Times, 20 mai 2022 ; Marcel Dorigny, Jean-Marie Dulix Théodat, Gusti-Klara Gaillard-Pourchet, Jean-Claude Bruffaerts (dir.), Haïti-France. La chaîne de la dette. Le rapport Mackau (1825), Paris, Hémisphères Éditions, 2021. ↑
- Jean Ziegler, L’empire de la honte, Paris, Fayard, 2005. ↑
- Porter et al., 2022, op. cit. ↑
- Gusti-Klara Gaillard-Pourchet, « Aspects politiques et commerciaux de l’indemnisation haïtienne », dans Yves Benot et Marcel Dorigny (dir.), Rétablissement de l’esclavage dans les colonies françaises. Aux origines de Haïti, Paris, Maisonneuve et Larose, 2003, p. 263. ↑
- François Blancpain, Un siècle de relations financières entre Haïti et la France (1825-1922), Paris, L’Harmattan, 2001. ↑
- Brière, 2008, op. cit. ↑
- Quijano, 1999, 2014, op. cit. ↑
- Blancpain, 2001, op. cit. ↑
- Porter et al., 2022, op. cit. ↑
- Alex Bellande, Haïti déforestée. Paysages remodelés, Montréal, Cidihca, 2015. ↑
- Nicolas Sersiron, Dette et extractivisme. La résistible ascension d’un duo destructeur, France, Utopia, 2014. ↑
- Zambrana, 2021, op. cit. ↑
- Alexandra Breaud, Aristide et la France. Lles raisons de la discorde, Paris, L’Harmattan, 2015. ↑
- Porter et al., 2022, op. cit. ↑

Pour une solution ayitienne durable, populaire et souveraine
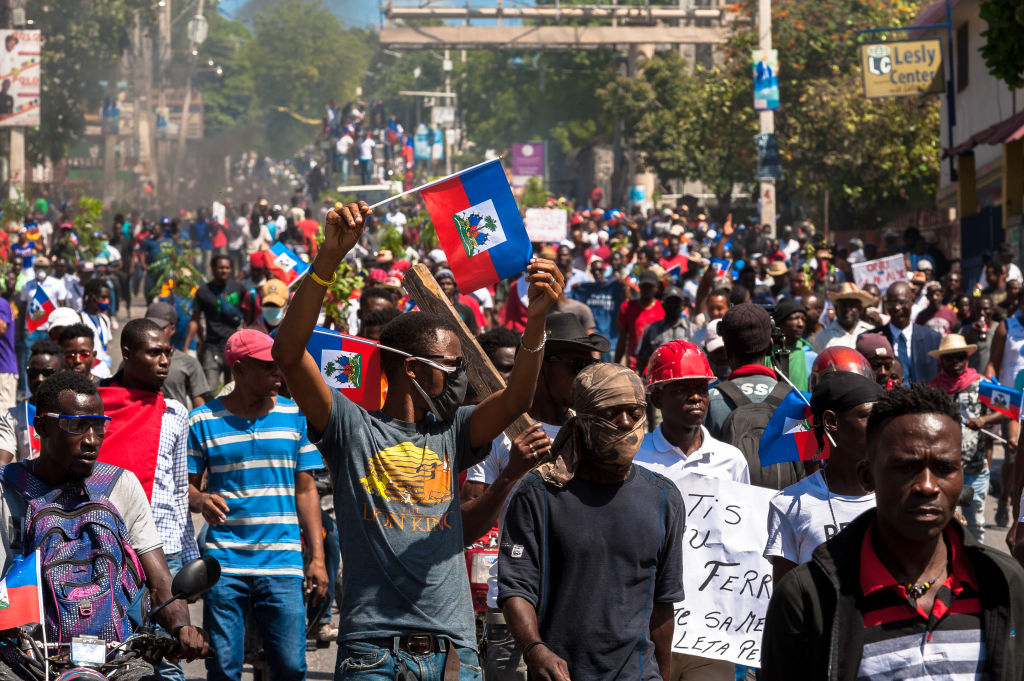
Cet article est tiré d’une présentation donnée dans le cadre du colloque La Grande Transition en mai 2025 à l’Université du Québec à Montréal.
La République d’Ayiti[1] traverse une crise multidimensionnelle, mêlant instabilité politique, pauvreté extrême, insécurité et dépendance économique. Cet article propose une analyse critique de cette crise, mettant en lumière les causes structurelles liées à la domination néocoloniale, au capitalisme et à l’exclusion sociale. Une lecture critique de la crise ayitienne insiste sur la nécessité d’une rupture radicale avec les logiques néolibérales et impérialistes, pour reconstruire un État populaire, souverain et autonome[2]. Il y sera discuté des pistes de solutions endogènes, fondées sur l’émancipation populaire, la reconstruction de la souveraineté nationale et l’autogestion communautaire, comme fondements d’un projet politique alternatif et durable.
Une crise fabriquée, pas une fatalité
Depuis l’indépendance en 1804, Ayiti subit les violences cumulées du colonialisme, de l’impérialisme et du capitalisme mondialisé, conditions structurelles qui expliquent la persistance de ses crises. La déstabilisation politique récurrente, l’accaparement des richesses par une élite liée aux intérêts étrangers et la marginalisation de la majorité populaire sont les conséquences directes d’un système socioéconomique inégalitaire et dépendant.
La crise profonde que traverse Ayiti n’est pas seulement une crise de gouvernance ni même une crise sécuritaire. Elle ne peut être comprise sans faire référence aux rapports de production et aux classes sociales. L’oligarchie haïtienne, en alliance avec des puissances étrangères, comme les États-Unis, et les institutions financières internationales, maintient la population dans une condition de prolétariat précarisé, exploité à la fois localement et dans le cadre du capitalisme mondial[3].
Voici quelques caractéristiques de la crise ayitienne :
– une exploitation économique : la majorité des travailleuses et travailleurs ruraux et urbains vivent de la subsistance ou de l’économie informelle, sans accès aux moyens de production ni aux ressources ;
– une dépossession historique : la rançon de 1825, paiement forcé d’indemnités à la France qui l’a réclamé en « dédommagement » de l’indépendance, ainsi que les interventions militaires et politiques étrangères ont affaibli l’appareil productif national[4].
– une dépendance et un néocolonialisme qui se perpétuent : les politiques imposées par la Banque mondiale et le Fonds monétaire international (FMI) structurent l’économie autour de l’exportation de l’industrie textile, de la sous-traitance[5] et de l’aide internationale, maintenant ainsi la dépendance d’Ayiti.
Regardons les faits contemporains. Ayiti est dans une situation d’effondrement, mais ce qui prévaut maintenant remonte à plus de 39 ans. Un bref survol de la question sécuritaire nous permet de le démontrer.
Les crises à la suite du départ de Duvalier fils de 1987 à 1994 ont été marquées du sceau des coups d’État et de répressions paramilitaires ainsi que d’une présence notable du narcotrafic. Les premiers germes du banditisme social faits de rapts, d’enlèvements, d’exécutions sommaires, d’incendie de bâtiments publics, etc., vont émerger vers la fin des années 1990 et seront encore plus nombreux pendant la période allant de 2004 à 2007. En même temps, on observe le démantèlement de l’armée[6] et l’instrumentalisation de la police déjà infiltrée par les organisations criminelles. « Le trafic de drogue et le crime organisé menacent d’anéantir irrémédiablement l’autorité de l’État… en Haïti, au Mexique et en Jamaïque », de dire John Negroponte, numéro deux du département d’État américain en 2008[7].
Cette spirale infernale de violence va s’accentuer durant la présidence de Michel Martelly et de Jovenel Moïse, périodes au cours desquelles les gangs armés seront instrumentalisés pour mater la résistance de la population face à une politique inique, corrompue et à relents dictatoriaux.
Ces gangs armés ont été fédérés à la suite de la recommandation d’Hélène Lalime, la représentante du Bureau intégré des Nations unies en Haïti (BINUH). Ils circulaient en toute impunité sous la présidence de Moïse, soulignant ainsi leur accointance de facto avec le pouvoir. Ce sont les mêmes gangs qui se sont relativement autonomisés et qui agissent aujourd’hui.
Ce détour était nécessaire pour éviter les raccourcis qui ne regardent la situation que de manière superficielle, voulant faire croire – c’est le discours dominant ou médiatique – qu’il y a une guerre civile en Ayiti. Il faut donc comprendre que cette situation délétère de banditisme social et politique ne date pas d’aujourd’hui et est la résultante de crises plus profondes dans la société.
Mais maintenant, quels sont les termes du problème ?
Un climat de terreur provoquant des déplacements massifs de personnes
Les gangs contrôlent et terrorisent des quartiers entiers (plus de 85 %) de la zone métropolitaine de la capitale, Port-au-Prince. Plus d’un million de personnes[8] sont des déplacé·e·s internes – un chiffre qui a triplé en un an : en décembre 2024, il s’agit du plus grand nombre de déplacements dans le monde en raison de la violence liée à la criminalité[9]. On déplore des milliers de morts : 4 239 entre le 1er juillet 2024 et le 28 février 2025 selon le Haut-Commissariat des Nations unies aux droits de l’homme (HCDH), dont plus de 90 % ont été tués par des armes à feu. Des milliers de femmes sont violées : 6 250 signalées en 2024 et 1 250 pour les seuls mois de janvier et février 2025 d’après les organismes de femmes et des droits de la personne[10]. Des résidences privées partent en fumée. Des institutions sont flambées ou pillées : universités, hôpital public, écoles secondaires, ministères, centre de documentation, hôtels, sites patrimoniaux, la liste n’en finit pas… Certaines villes de province sont aussi tombées aux mains des gangs armés dans le département du Centre, l’Artibonite, Saut-d’Eau, Mirebalais. L’étau se resserre sur le pays.
L’État est totalement absent et l’appareil gouvernemental est incapable d’agir, ou plutôt, il y a une totale absence de volonté d’agir, ceci dans le but de faire durer la crise afin de laisser la place à une solution concoctée par les puissances qui imposent leurs diktats au Conseil présidentiel de transition[11] et consorts, pour qu’elles jugulent la crise et l’avancée inexorable des gangs mieux armés que les forces de l’ordre – l’ONU estime qu’entre 270 000 et 500 000 armes à feu circulent de manière illicite, la plupart entre les mains des gangs. Les forces de l’ordre, supportées par « les puissants amis d’Ayiti », n’arrivent pas à mettre au pas les bandes armées alors qu’elles n’ont pourtant aucune difficulté à disperser les manifestations citoyennes. La provenance des armes et munitions des gangs est une évidence sachant qu’Ayiti ne les fabrique ni ne les produit et qu’il y a en principe un embargo sur ce pays concernant l’achat d’armes. On constate également l’accaparement de terres agricoles ou à visée touristique stratégique.
Pendant que tout est fait pour empêcher une stabilisation de la situation afin de permettre la vie au pays, des rapatriements de masse, au sens de retours massifs imposés à ceux et celles qui ont quitté Ayiti, sont effectués par ceux-là mêmes qui provoquent et alimentent le chaos. Plus de 200 000 Ayitiennes et Ayitiens sont menacés de déportation des États-Unis d’Amérique du Nord, près de 200 000 ont été refoulés de force en 2024 dont 97 % depuis la République dominicaine. Les autres triment et vivent le racisme primaire ou la xénophobie, et le mépris dans les autres pays où ce peuple se trouve désormais disséminé. Cette tragédie a des répercussions non seulement sur les personnes de la communauté ayitienne de la diaspora, telles que le stress, la détresse, les pertes économiques, mais aussi à l’intérieur du pays puisque des centaines de milliers de personnes survivent et échappent en partie à la famine grâce aux transferts financiers ou en nature effectués directement par les migrantes et migrants à l’intention de leur famille ou de leur communauté.
Échec total des « solutions » imposées et faillite des élites locales
Cette situation ne vient pas de nulle part. Elle est enracinée dans l’histoire longue de domination, d’inégalités, de dépossession du peuple ayitien. Et surtout, c’est une crise où la voix, les besoins et les aspirations du peuple sont étouffés, exclus des processus de décision.
Depuis plus d’un siècle, Ayiti subit une série d’interventions ou d’ingérences étrangères qui n’ont jamais respecté sa souveraineté. À titre illustratif, mentionnons :
- l’occupation américaine de 1915 à 1934 ;
- le soutien occidental à la dictature des Duvalier ;
- les interventions armées depuis les années 1990 ;
- la Mission des Nations unies pour la stabilisation en Haïti (MINUSTAH), déployée de 2004 à 2017, censée « stabiliser » le pays, mais qui a laissé un héritage de violences sexuelles, d’impunité, et même… une épidémie de choléra. On parle de 20 ans de missions onusiennes (MINUSTAH et Bureau intégré des Nations unies en Haïti, BINUH) et de milliards dépensés qui n’ont donné aucun résultat durable ;
- l’ingérence dans les élections (Michel Martelly, Jovenel Moïse) ;
- l’imposition d’Ariel Henry par un tweet du consortium des ambassadeurs du Core Group ;
- l’imposition par les puissances internationales du Conseil présidentiel de transition pour mettre en œuvre leur propre projet pour Ayiti (élections, référendum, constitution) et la mise à l’écart de toute initiative visant à une véritable transformation de la société ;
- la décision d’envoyer une force « anti-gang » en Ayiti qui vient d’être votée aux Nations unies le 26 septembre 2025.
Aujourd’hui encore, les décisions sont prises à Washington, Ottawa, Paris ou à l’ONU – pas à Port-au-Prince, pas à Ouanaminthe, pas à Cité Soleil, pas à Raboteau…
Comme on peut le voir, la crise, ou plutôt les crises que traverse Ayiti actuellement, n’est donc pas une crise ayitienne. C’est une crise du système impérialiste en Ayiti. C’est le résultat d’une logique et d’un projet néocolonial fait d’ingérences, de décennies de pillages, de tutelles, de cooptation politique, d’ONGisation du pays, de missions dites « de paix » qui ont détruit l’État.
Concrètement, ces missions étrangères n’ont pas renforcé l’État ayitien, elles l’ont remplacé. Elles ont protégé des gouvernements corrompus, pas le peuple. Elles occupent le terrain mais ne construisent rien de durable. Elles sont accompagnées d’une aide humanitaire qui arrive par avion, distribuée par les ONG, pendant que l’État ayitien est tenu à l’écart. Les élites haïtiennes, souvent complices, ont abandonné le peuple pour le profit et le pouvoir. Ces élites politiques corrompues accaparent le pouvoir avec la bénédiction de la « communauté internationale ».
Le résultat de cette conjonction entre l’aide internationale et les élites rapaces, cleptomanes, se résume ainsi : 60 % de la population vit sous le seuil de pauvreté ; le Parlement est dysfonctionnel ; des gangs armés contrôlent des quartiers, des routes et même des villes.
Chacune des interventions étrangères a affaibli un peu plus la souveraineté d’Haïti. Pendant ce temps, les Ayitiens et Ayitiennes continuent à vivre dans l’angoisse permanente, c’est-à-dire dans la peur des enlèvements, de la faim, de l’exil forcé.
Les soi-disant « solutions » importées ont désarmé la société haïtienne au lieu de l’accompagner dans son émancipation. Elles ont détruit la capacité d’organisation autonome du peuple. Elles ont rendu l’État dépendant, inefficace, fantomatique. Il est temps de rompre avec cette logique d’assistance permanente qui infantilise le peuple ayitien.
Une solution ayitienne, populaire et souveraine
Aujourd’hui, il est temps de dire : la solution viendra des Ayitiens et des Ayitiennes eux-mêmes et elles-mêmes. Une solution ayitienne est impérative : une solution populaire et souveraine.
La résistance du peuple ayitien se poursuit, malgré une situation socioéconomique très difficile et un quotidien fait d’angoisse, d’incertitude et de chagrin. À mains nues et sans le soutien du gouvernement, la population agit pour limiter les nuisances causées par les bandes armées et les enlèvements en série. Cette action s’accompagne d’une colère à la hauteur des agressions, de la mort et des rançons. La situation a un impact énorme sur la « transnation » de la diaspora, en particulier sur les couches précaires qui doivent soutenir leurs proches à Ayiti.
Malgré ce sombre tableau, la population ayitienne prend des initiatives. Ainsi l’érection du canal de la dignité à la frontière ayitiano-dominicaine, grâce aux expertises ayitiennes, à des fonds de la diaspora et de certaines régions du pays, porte déjà fruit : la filière rizicole reprend vie dans la zone[12]. Notons aussi l’acte héroïque de cette population qui a décidé d’empêcher la réouverture de la frontière après l’arrogante fermeture par la République dominicaine. La solidarité active des régions non infestées par les gangs qui reçoivent et hébergent des milliers de déplacé·e·s en dépit de leur propre vulnérabilité est remarquable. Enfin, des expériences d’agriculture biologique se mettent en place, démarrées surtout par les organisations paysannes et les organisations de femmes.
Aujourd’hui, les forces vives ayitiennes pensent que l’alternative ne saurait être qu’ayitienne et se construit sans bruit au sein des masses. En attendant, il faut régler la question sécuritaire – démanteler les gangs –, créer des opportunités économiques pour occuper les jeunes et diminuer le chômage, continuer à promouvoir le nécessaire retour aux processus démocratiques, rebâtir les institutions étatiques, rendre justice, redonner confiance à la population.
Cette solution doit se construire autour des axes suivants qui ne constituent cependant que des pistes de réflexion.
Refondation démocratique
Une solution durable passe par une refondation de la démocratie participative et populaire s’appuyant sur un dialogue inclusif qui rassemble les forces vives de la nation, vraies bâtisseuses de la démocratie : les mouvements sociaux, les collectivités territoriales, les syndicats, les comités de quartier, les organisations populaires de jeunes, la frange progressiste de la diaspora.
Il faut redonner du pouvoir aux structures locales (CASEC[13], ASEC[14]) et aux conseils communaux, en leur donnant des moyens réels. Cette nouvelle démocratie serait enracinée dans le peuple car c’est lui qui doit écrire les règles du jeu et non les ambassades.
La sécurité par le peuple, pour le peuple
On ne peut parler de solution sans aborder la question de l’insécurité. Mais, il ne s’agit pas de répondre par des interventions militaires étrangères, encore moins de recourir à des mercenaires, comme c’est le cas maintenant, ou à des opérations répressives aveugles ni par l’envoi d’une nouvelle force militaire étrangère, sorte d’occupation déguisée.
Il s’agit plutôt de réfléchir à un désarmement, construit avec les communautés, à des programmes de réinsertion, de formation et de réparation pour les très jeunes, qui sont engagés dans la criminalité et instrumentalisés. En même temps, il faut une reconstruction de la police formée sur les droits de la personne.
Parallèlement, une justice transitionnelle doit être mise en place : pour juger les crimes politiques, les abus de pouvoir et rendre justice aux victimes. Il faut aussi encourager des formes de justice communautaire, encadrée, enracinée dans les pratiques locales. Il existe déjà dans les campagnes, à travers le vaudou, des mécanismes et des pratiques traditionnelles pour gérer et régler les conflits communautaires.
Un projet économique radicalement différent : une relance économique populaire
Le modèle néolibéral actuel enrichit une minorité et détruit toute velléité de production nationale. Il faut relancer l’économie populaire par :
- une réforme agraire qui redistribue la terre aux paysans, propulsant ainsi la revitalisation de l’agriculture paysanne ;
- la mise sur pied de coopératives autogérées agricoles et artisanales, financées par l’État et les banques publiques, dans lesquelles les paysans, paysannes, travailleurs et travailleuses détiennent collectivement les outils de production. Ce modèle permettrait de relancer une agriculture vivrière indépendante, garante de souveraineté alimentaire[15] ;
- une politique de protection du marché local, pour permettre aux productrices et producteurs ayitiens de survivre face aux importations étrangères et de s’éloigner du modèle néolibéral qui repose sur le développement de zones franches, des importations massives et de la dette ;
- la lutte contre la corruption.
Donc, ce qu’il faut, ce n’est pas une aide d’urgence, mais un projet de société ayitien construit sur les réalités du pays, non sur les rapports de la Banque mondiale. Aucun avenir ne peut se bâtir sans la reconquête de notre autodétermination.
Des services publics pour toutes et tous
Un pays ne se construit pas sans éducation, sans santé, sans services de base. L’État doit devenir un acteur central du développement, au lieu d’être un simple gestionnaire de misère.
Reconquête de la souveraineté politique et économique
Toute solution durable doit reposer sur la souveraineté nationale. Cela signifie rompre avec la dépendance aux puissances impérialistes, choisir ses alliances. Cela signifie travailler avec les pays du Sud global, notamment les Caraïbes et l’Afrique, redéfinir notre rapport à l’importation, à l’aide internationale.
Et surtout mettre fin à la domination de l’économie par une élite compradore, l’oligarchie, alliée aux intérêts étrangers.
Conditions de réussite et obstacles
Bien sûr, une telle transformation ne sera pas facile. Les obstacles sont nombreux. L’oligarchie économique défendra ses privilèges ; des puissances étrangères refuseront une Ayiti souveraine ; des structures armées chercheront à saboter toute alternative.
Mais rien de cela ne pourra tenir si le peuple est organisé. La clé, c’est la mobilisation populaire : des syndicats, des mouvements de femmes, des étudiants et étudiantes, des paysans et paysannes. C’est aussi l’éducation politique : redonner au peuple les outils pour comprendre, critiquer et agir. Cela permettra de juguler la crise de confiance.
Conclusion
« Se pa etranje k ap sove Ayiti. Se Ayisyen k ap fè sa, ansanm[16] ».
Nous avons essayé toutes les solutions venues d’en haut et elles ont échoué. Aujourd’hui, il est temps de faire confiance à la force du peuple haïtien, à son intelligence, à sa dignité.
Une solution durable de gauche n’est pas une utopie, c’est une nécessité. C’est la seule voie qui place l’humain, le peuple, la justice sociale et la souveraineté au cœur du projet national. La solution viendra des entrailles du peuple ayitien, de sa capacité à se relever, à s’unir, à s’organiser. Aujourd’hui, plus que jamais, il est temps de les écouter, et de reconstruire avec eux et elles — et non sans eux et elles — une Ayiti libre, juste et digne.
Et notre rôle, ici, maintenant, c’est de porter cette voix, de la relayer, de la renforcer, pour que plus jamais personne ne dise qu’Ayiti est incapable de se gouverner. Ayiti est debout. Et tant qu’elle résiste, nous devons être à ses côtés. En ce sens, il est important d’activer la solidarité entre les peuples. L’appel qui suit commence par une interpellation pour ici et maintenant.
Vive la solidarité entre les peuples !
Appel à la solidarité internationaleLes Ayitiens et Ayitiennes font appel à une solidarité des peuples. Pas à une solidarité d’ONG ni de diplomates.
Nous n’avons pas besoin d’occupation. Nous avons besoin de respect. Nous avons besoin que le monde écoute enfin ce que dit le peuple ayitien. L’avenir d’Ayiti ne viendra ni d’une caserne ni d’un bureau d’ambassade. Il viendra des luttes locales, de la solidarité internationale des peuples, de la capacité du peuple ayitien à s’organiser et à décider pour lui-même. Plus que jamais, Ayiti a besoin de ses allié·e·s. Il est impératif d’être solidaire du peuple d’Ayiti, de ses mouvements populaires et de sa classe ouvrière en lutte et réclamant son droit à la sécurité et à l’autodétermination. À l’heure où Ayiti dépérit sous les coups répétés des gangs armés téléguidés par l’oligarchie tant ayitiene qu’internationale, où Ayiti s’agenouille sous les assauts continus des forces impérialistes, néolibérales autant des grands ténors que des forces émergentes, où Ayiti s’enfonce dans une crise sociale, économique, écologique, sanitaire, humanitaire sans précédent dans l’indifférence de ses dirigeantes et dirigeants menés par leurs intérêts personnels et inféodés aux intérêts étrangers, où les Ayitiennes et les Ayitiens sont pourchassés, humiliés, vilipendés, refoulés de manière arbitraire et inhumaine presque partout au Nord et même au Sud, le silence complice, voire coupable, des forces progressistes, retentit dans le cœur meurtri de la communauté ayitienne. Devant cette indifférence contraire aux principes de la solidarité internationale et aux intérêts trans-stratégiques des luttes dans le contexte actuel de montée de la droite, du fascisme, du racisme, nous nous questionnons sur les raisons de cette posture et nous nous inquiétons en tant que Québécois, Québécoises et néoQuébécois, néoQuébécoises sur la nécessaire vitalité du secteur progressiste. Nous constatons l’apathie des forces progressistes du Québec. Nous nous inquiétons aussi pour l’avenir de notre terre d’adoption dans la conjoncture mondiale. Ceci est un cri de nos entrailles déchirées, une sonnette d’alarme pour un réveil des forces progressistes du Québec et d’ailleurs à contribuer au grand faisceau de solidarité planétaire nécessaire et urgente face à l’alliance néolibérale, fasciste, impérialiste et coloniale des forces rétrogrades. Progressistes de tous les pays unissons-nous ! Ce combat est celui de toute la gauche internationale ! Et vive la lutte du peuple ayitien ! |
Par Chantal Ismé, militante féministe internationaliste
- On a repris l’ancien nom donné par les Taïnos qui en même temps correspond à la graphie du créole. ↑
- Jean-Alix René, Haiti après l’esclavage. Formation de l’État et culture politique populaire (1804-1846), Communication Plus, 2019. ↑
- Samir Amin, Le développement inégal. Essai sur les formations sociales du capitalisme périphérique, Paris, Éditions de Minuit, 1973. ↑
- Michel-Rolph Trouillot, Silencing the Past. Power and the Production of History, Boston, Beacon Press, 1995. ↑
- Actuellement remise en question par le non-renouvellement de la loi Hope/Help en raison des tarifs de Trump. ↑
- Rétablie, officiellement du moins, par Moïse Jovenel [NDLR]. ↑
- Cité dans Claude Moïse, La question sécuritaire, d’une année à l’autre. Similarités entre 2004-2007 et 2020-2022, CIDIHCA et Zémès SA, 2022, p. 97. ↑
- 1 041 229 de déplacé·e·s d’après les chiffres de l’Organisation internationale pour les migrations (OIM), Rapport sur l’état de la migration dans le monde, 2024. ↑
- Ibid. ↑
- Source : Organisation panaméricaine de la santé (OPS). ↑
- Le Conseil présidentiel de transition a été formé le 12 avril 2024, un mois après la démission du premier ministre Ariel Henry dont le gouvernement assure l’intérim après l’assassinat de Jovenel Moïse en 2021. ↑
- Au moment de publier cet article, les bandes armées ont mis le feu dans plusieurs plantations rizicoles. ↑
- Conseil d’Administration de la Section Communale. ↑
- Assemblée de Section Communale. ↑
- René, 2019, op. cit. ↑
- Ce n’est pas l’étranger qui sauvera Ayiti. Ce sont les Ayitiens et Ayitiennes qui le feront ensemble. ↑






